
Минулий пост було присвячено тому, як обрати найкращий алгоритм керованої класифікації. А зараз ми розберемо, як виконувати керовану класифікацію у програмі ENVI. Зробимо це на прикладі класифікації за алгоритмом паралелепіпеду – математично найпростішого алгоритму. В ENVI робота з усіма іншими способами керованої класифікації мало відрізняється від роботи з ним. Інтерфейс налаштування процедури класифікації для всіх алгоритмів практично однаковий. Відмінність між ними є лише у параметрі, що задає чутливість процедури. Тому якщо користувач оволодіє навичкою роботи в ENVI з алгоритмом паралелепіпеда, він чи вона легко зможе працювати у цій програмі й з іншими алгоритмами керованої класифікації.
Теорія
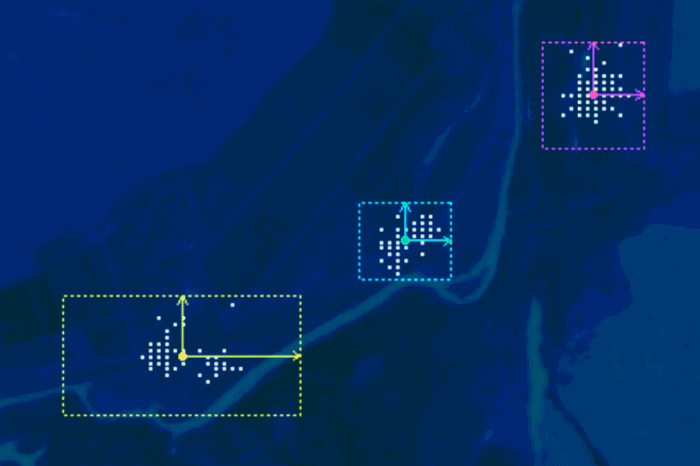
Але спочатку трохи теорії. Для наочності візьмемо найпростіший випадок – двомірний простір спектральних ознак (рис. 1). У ньому треба виокремити декілька класів. На рисунки 1 ми чітко бачимо три хмари значень, що відповідають трьом класам. Вони не перетинаються одна з одною. Тому це саме той випадок, коли треба використати класифікацію паралелепіпеда.

Рис. 1. Умовний приклад ситуації, де для виокремлення класів буде ефективним алгоритм паралелепіпеда
Для класифікації паралелепіпеда програмі треба знати для кожного класу два параметри. Це середнє значення яскравості та стандартне відхилення від середнього у всіх каналах знімка. В умовному прикладі на рисунку 1 ми маємо два канали, тому й простір спектральних ознак є двомірним. Обидва параметри, які необхідні для класифікації, програма вираховує з навчальних вибірок, що створив користувач.
Процес класифікації має три етапи (рис. 2). На першому етапі програма встановлює у просторі спектральних ознак центри кожного класу. Саме для цього їй треба знати середні значення яскравості класів у всіх каналах знімку. На рисунку 2А центри трьох класів позначені кольоровими колами – червоним, синім і зеленим.
Далі програма знаходить крайні точки кожного класу. Для цього вона відкладає від центра класу паралельно осям простору спектральних ознак лінії. Їх довжина дорівнює декільком стандартним відхиленням. Точний її розмір завдає користувач, і від цього налаштування залежить чутливість класифікації. Цей розмір може бути однаковим для всіх класів, а може й відрізнятися.
На рисунку 2B показаний другий етап класифікації. Для червоного класу відкладено 3 стандартних відхилення, а для зеленого та синього класу – 4 стандартних відхилення.
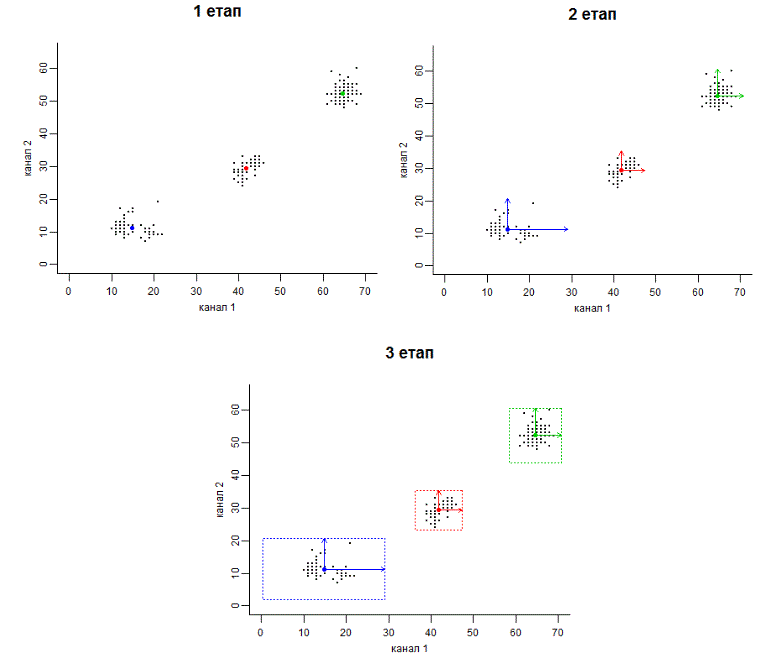
Рис. 2. Етапи класифікації за алгоритмом паралелепіпеда
На останньому етапі (рис. 2С) програма через крайні точки, паралельно осям, поводить лінії, що обмежують класи. Усі значення, що опиняються всередині, вона зараховує до відповідного класу. На рисунку 2 ми бачимо, що геометрична фігура, яка обмежує класи – це паралелепіпед. Саме від цього алгоритм класифікації отримав свою назву. У тривимірному просторі спектральних ознак класи буде обмежувати вже паралелограм. А якщо каналів у знімку буде більше, ніж три – то так званий гіперпаралелепіпед.
Практика
Практику класифікації за алгоритмом паралелепіпеда розберемо на вже знайомому прикладі. Це фрагмент космічного знімка Landsat 5 TM за 16 вересня 2009 року (рис. 3). На території навколо Сіверського Дінця біля Мохнача треба виокремити три класи об’єктів – листяні ліси, хвойні ліси та водойми.
 |
 |
Рис. 3. Фрагмент знімка Landsat (зліва) та навчальна вибірка (справа)
1) Всі процедури класифікації з навчанням (керованої класифікації) починаються зі створення навчальної вибірки (користувацького еталона). Це і є процес навчання класифікації. В ENVI він реалізується через створення областей обробки.
Для кожного класу створюйте свою окрему область обробки. Потім треба перевірити створені області обробки з точки зору якості навчальних вибірок (докладніше про це розповідає пост «Якісні навчальні вибірки для керованої класифікації»).
2) За допомогою n-D Vizualizer визначте як розташовані у багатомірному просторі спектральних ознак хмари точок, що відповідають класам (детальніше про n-D Vizualizer читайте у пості «Багатовимірний простір спектральних ознак та робота з ним в ENVI»). Якщо вони не перетинаються одна з одною, то ми маємо використовувати класифікацію паралелепіпеда.
3) Коли навчальні вибірки створені, можна запускати процедуру класифікації. Для цього виберіть у Тулбоксі команду Classification→Supervised Classification→Parallelepiped Classification. Після цього з’явиться вікно Classification Input File. Виберіть в ньому зображення, яке треба класифікувати.
4) Після обрання знімка для класифікації з’явиться вікно Parallelepiped Parameters. В ньому треба налаштувати параметри процедури класифікації за алгоритмом паралелепіпеду. Є чотири параметри, котрим відповідають окремі блоки вікна (Parallelepiped Parameters):
- перелік областей обробки (блок Select Classes from Regions:)
- максимальне стандартне відхилення від середнього (блок Set Max stdev from Mean)
- налаштування збереження результату класифікації (блок Output Result to).
налаштування збереження зображень правил (блок Output Rule Images?)

Рис. 4. Вікно Parallelepiped Parameters
5) В переліку областей обробки знаходяться всі області обробки, що були нанесені на знімок у поточному сеансі роботи з ENVI. Але ми можемо бажати використовувати як навчальні вибірки не всі області, а лише деякі. Тому за умовчанням жодної з них не обрано. Оберіть їх за допомогою лівої кнопки миші. А якщо все ж треба обрати всі області обробки, що існують, то натисніть кнопку Select All Items. Натиснення кнопки Clear All Items зніме виділення зі всіх областей обробки.
6) Налаштуйте максимальне стандартне відхилення від середнього. В ENVI існує три варіанти налаштування цього показника: None, Single Value, Multiple Values. Приклади результатів, що дають ці варіанти, на рисунку 5.

Рис. 5. Результати класифікації за різних налаштувань стандартного відхилення від середнього. A – None, B – Single Value (стандартне відхилення дорівнює 3), C – Single Value (стандартне відхилення дорівнює 4), D – Multiple Value (стандартне відхилення для водойм дорівнює 3.5, для листяних лісів – 5,0, для хвойних лісів – 6,0)
А) Якщо вибрати варіант None, буде використовуватися нульове значення. Нічого вводити у цьому разі не треба. Процедура класифікації буде шукати тільки ті пікселі, що строго рівні середньому значенню класу, котре задано областю обробки. Скоріше за все, при такому налаштуванні значення площ класів будуть дуже занижені (рис. 5А).
Б) За замовчуванням стоїть варіант Single Value – однакове значення для всіх класів. Цей варіант буде оптимальний коли в багатомірному просторі спектральних ознак хмари значень класів мають однаковий розмір або їх розміри не дуже відрізняються. Якщо вони мають різний розмір, то в деяких випадках теж можна використовувати однакове значення максимального відхилення від середнього. Це можливо, коли відстань між хмарами достатньо велика. Таким чином паралелепіпеди, розмір котрих задає розмір найбільшої хмари значень, не перетинаються один з одним.
У варіанті Single Value за замовчанням максимальне стандартне відхилення від середнього дорівнює 3,00. Користувач може поставити інше значення, яке буде оптимальним у конкретному випадку. Якщо значення буде нижче оптимального, площа класів буде меншою за реальну, тобто виникнуть помилки пропускання. Це ми бачимо на рисунки 5В, де серед ареалів лісів є білі плями. Якщо значення буде вище ніж оптимальне, площа класів буде завищена, тобто виникнуть помилки приписування. Приклад цього на рисунки 5С, де водойм виокремлено набагато більше, ніж є насправді на цій території.
В) Якщо у багатомірному просторі спектральних ознак хмари значень класів мають різний розмір (діаметр) та розташовані близько одна від одної, то треба використовувати варіант Multiple Values. Якщо Ви встановите перемикач на цей варіант, то поле для вводу значення зникне, а замість нього з’явиться кнопка Assign Multiple Values. Натисніть її, з’явиться вікно Assign Max stdv from Mean. У ньому є перелік областей обробки та поле для введення значень (Edit Select Item:). Треба по черзі виділити кожну область обробки та задати для неї значення максимального стандартного відхилення від середнього.

Рис.6. Налаштування стандартного відхилення окремо для кожного класу
7) Налаштуйте спосіб збереження результатів класифікації. Це може бути збереження у тимчасовій пам’яті (Memory) або збереження у файлі (File).
8) Налаштуйте спосіб збереження зображень правил. Про зображення правил зараз не будемо детально розбирати. Скажемо лише, що це зображення, на котрих показані площі класів, котрі вони будуть займати при різних значеннях параметру класифікації (для класифікації паралелепіпеду це максимальне відхилення від середнього). Зображення правил використовують для так званої класифікації на основі правил (Rule-based classification) і створення ROC-кривих (це спосіб оцінки точності класифікації). Про ці процедури будуть окремі пости. Якщо Ви не збираєтесь робити такі класифікації, то Вам не потрібно зберігати зображення правил. У такому разі поставте перемикач на значення No (за умовчанням стоїть значення Yes). Як і результати класифікації, зображення правил теж можна зберігати у тимчасовій пам’яті або у постійному файлі.
9) Після всіх налаштувань можна відразу натиснути кнопку OK та отримати результат класифікації. Але якщо Ви неправильно налаштували параметр максимального відхилення від середнього, якість класифікації буде незадовільною. Тому в ENVI передбачена можливість перевірити якість класифікації заздалегідь, за допомогою попереднього перегляду її результатів. Для цього натисніть кнопку Preview (рис. 7). Після цього вікно Parallelepiped Parameters розшириться, в його правій частині з’явиться блок попереднього перегляду (Classification Preview) з фрагментом зображення класифікації.

Рис. 7. Попередній перегляд результатів класифікації
10) За замовчуванням попередній перегляд робиться на фрагменті знімку розміром 256 на 256 пікселів, що розташований у центрі знімку. Щоб змінити фрагмент знімку для попереднього перегляду, натисніть кнопку Change View…

Рис. 8. Зміна фрагмента знімка, що використається для попереднього перегляду результатів класифікації
З’явиться вікно Select Spatial Subset у якому можна обрати інший фрагмент знімку. Зробити це можна двома способами. Можна ввести точні екранні координати для верхнього лівого кута фрагменту знімка. Для цього використаються поля Samples і Lines. Але скоріше за все вам більш подобається інший спосіб – візуальне виокремлення фрагменту. Щоб скористатися ним натисніть у вікні Select Spatial Subset кнопку Image (рис. 8, зліва). З’явиться вікно Subset by Image в якому показаний увесь знімок в зменшеному масштабі та червоною прямокутною рамкою обведений фрагмент для попереднього перегляду (рис. 8 справа). Клацніть лівою кнопкою миші по червоній рамці. Втримуючи лівою кнопкою миші перетягніть рамку на нове місце та натисніть кнопку OK. У вікні Select Spatial Subset теж треба натиснути кнопку OK і після цього зображення у попередньому перегляді автоматично оновиться.
11) Якщо Ви незадоволені результатами, які бачите при попередньому перегляді, то змінить значення максимального відхилення від середнього. Після цього знов натисніть кнопку Preview. Шляхом проб і помилок Ви знайдете оптимальне значення максимального відхилення від середнього й отримаєте якісний результат класифікації.



Thanks for beautiful article. Enjoyed reading it. Minor error in the description
parallelogram is 2D
parallelopiped is 3D
Yes, this is a true remark