На нашому сайті вже був пост, присвячений одному з алгоритмів керованої класифікації – алгоритму паралелепіпеда. Зараз розберемо інший доволі популярний алгоритм – спосіб мінімальної відстані. На відміну від алгоритму паралелепіпеда, його використовують, коли яскравості класів перетинаються у багатомірному просторі спектральних ознак (детальніше про вибір алгоритму керованої класифікації у цьому пості).
Теорія
Розберемо теоретичні засади алгоритму мінімальної відстані на умовному прикладі. Щоб було легше їх проілюструвати, візьмемо найпростіший випадок – двомірний простір спектральних ознак. Він наведений на рисунку 1. Осі цього графіку відповідають двом каналам знімку. Пікселі космічного знімку – це точки у просторі спектральних ознак. На рисунку 1 є три класи, що позначені дрібними точками червоного, зеленого та синього кольору. Хмара червоних точок має перетин з хмарами зелених і синіх точок. Також є чорні точки. Вони не належать до жодного класу. Після виконання класифікації у карті класифікації їм будуть відповідати некласифіковані пікселі.
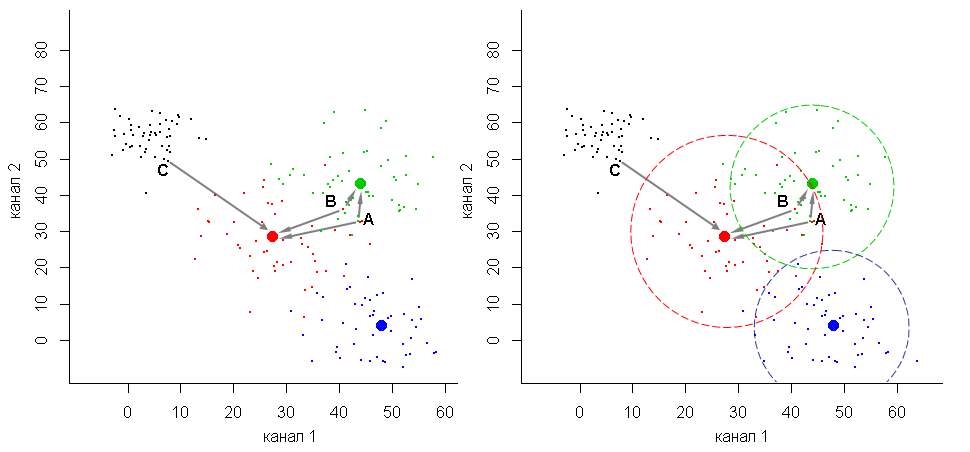
Рис. 1. Умовний приклад ситуації, де для виокремлення класів буде ефективним алгоритм мінімальної відстані
Коли ми класифікуємо зображення, то можемо припускати наявність некласифікованих пікселів або ні. У цих двох випадках процес класифікації за алгоритмом мінімальної відстані буде трохи відрізнятися. Але завжди він складається з трьох етапів.
На першому етапі програма для кожного класу вираховує координати центрів класів. Вони позначені на рисунку 1 колами, що мають відповідно червоний, зеленій і синій колір.
На другому етапі для кожного пікселя вираховуються відстані (дистанції) до центрів класів.
На третьому етапі йде порівняння дистанцій. До якого центру дистанція найменша, до того класу й буде зарахований піксель зображення. Саме тому алгоритм класифікації й отримав свою назву – алгоритм мінімальної відстані.
На рисунку 1 ліворуч ситуація, коли класифікація не передбачає можливості існування некласифікованих пікселів. А рисунок 1 праворуч – це, навпаки, випадок з некласифікованими пікселями у результатах класифікації. Сірими стрілками показані відстані від зеленої точки A та червоної точки B до центрів зеленого та червоного класів. Ми бачимо, що для обох точок до центру зеленого класу дистанція найменша. Тому точки A та B класифікація мінімальної відстані зарахує до зеленого класу. Тут ми бачимо й принцип визначення належності до класу, й джерело помилок класифікації. Але кількість помилок буде меншою, ніж коли ми обмежуємо класи прямокутниками, як при класифікації за алгоритмом паралелепіпеда. Саме тому при перетинанні яскравості класів рекомендують використати алгоритм мінімальної відстані, а не алгоритм паралелепіпеда.
Якщо ми припускаємо наявність некласифікованих пікселів, то алгоритм мінімальної відстані трохи ускладнюється. На рисунку 1 позначена чорна точка С. Найближчій до неї центр – це центр червоного класу. Щоб процедура класифікації не зарахувала її до складу цього класу, треба обмежити радіус пошуку навколо центрів. Для цього встановлюють максимально допустиму відстань від центру класу. На рисунки 1 праворуч наведений приклад цього. Максимальні відстані від центрів класів, що обмежують радіус пошуку, позначені пунктирними лініями. Без цього обмеження більшість чорних точок були б зараховані до червоного класу, а деякі – до зеленого (рис. 1, ліворуч). З обмеженням (рис. 1, праворуч) вони залишаться некласифікованими.
Можна для всіх класів завдавати однакове обмеження пошуку. Так треба робити, коли всі класи мають однакове розповсюдження значень. Якщо класи дуже відрізняються за розкидом значень, то треба завдавати для кожного класу свій розмір радіусу пошуку. Саме такий випадок показаний на рисунку 1 праворуч, коли для червоного класу припускається більша відстань від центру класу, ніж для синього або зеленого класів.
Практика
Практичну реалізацію алгоритму мінімальної відстані у програмі ENVI ми розберемо на приклади дешифрування лісової рослинності та водойм на космічному знімку. Фрагмент цього знімку наведений на рисунку 2 зліва. Знімок був зроблений з борту американського супутника Terra 16 вересня 2015-го року за допомогою апаратури ASTER VNIR. Він охоплює заплаву річки Сіверський Донець на межі Зміївського та Балаклійського району Харківської області, між селами Черкаський Бишкин і Нижній Бишкин на заході та селищем міського типу Андріївка на сході.
На знімку треба виокремити три класи: водні поверхні, хвойні ліси та листяні ліси. Серед водойм там є русло Сіверського Дінця, чисельні стариці на заплаві та акваторія озера Лиман. Листяні ліси представлені переважно дрібнолистими заплавними лісами на лівому березі Дінця та широколистим урочищем Тюндик на правому березі. Хвойні ліси – це Андріївський Бір, що росте на лівобережній терасі Дінця, між його заплавою та озером Лиман.
Знімок ASTER VNIR – це три канали з просторовою роздільною здатністю 15 м/піксель. Канали охоплюють зелену, червону та інфрачервону частину спектра. На рисунку 2 знімок показаний у RGB-комбінації каналів 3-2-1 (інфрачервоний – червоний – зелений). У цій комбінації хвойні ліси мають бордовий колір, а листяні ліси – яскраво-червоний. Водойми відзначаються чорним або темно-синім кольором.
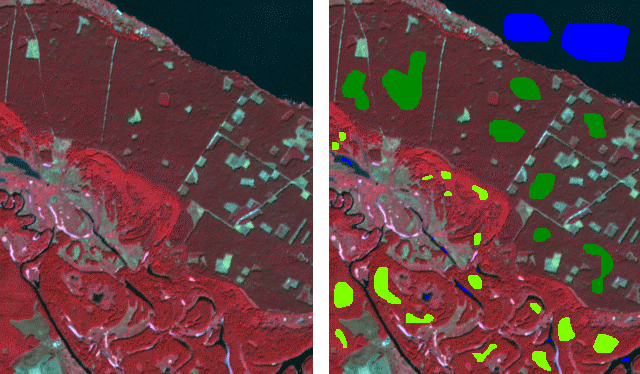
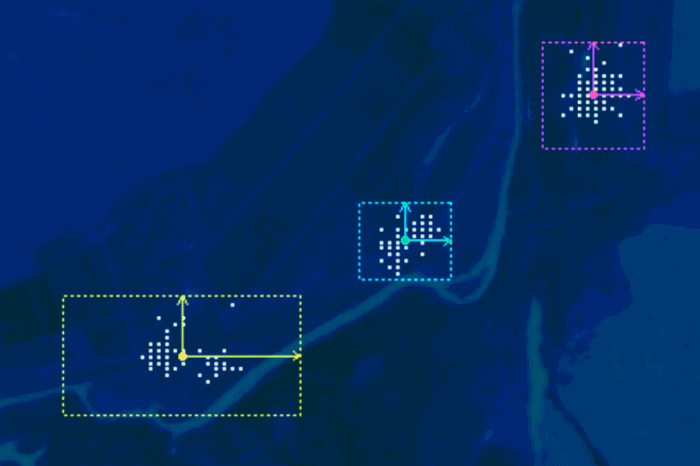
Рис. 2. Фрагмент знімка ASTER (зліва) та навчальна вибірка (справа)
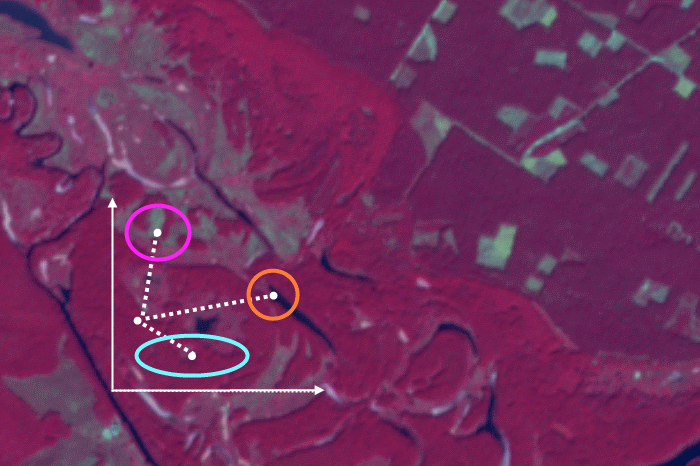
Навчальні вибірки для трьох класів наведені на рисунку 2 праворуч. Якщо проаналізувати розміщення пікселів цих вибірок у тривимірному просторі спектральних, то ми побачимо, що вони перетинаються одна з одною (рис. 3). Тому у цьому випадку треба застосувати для керованої класифікації зображення алгоритм мінімальної відстані.
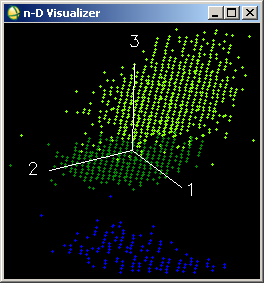
Рис. 3. Навчальні вибірки у тривимірному просторі спектральних ознак
Отже, ми переконалися у тому, що нам дійсно треба використати алгоритм мінімальної відстані. А далі пройдемо всі кроки процесу класифікації.
1) Щоб почати процес класифікації виберіть у тулбоксі команду Classification→Supervised Classification→Minimum Distance Classification (рис. 4). Після цього з’явиться вікно Classification Input File. Виберіть в ньому зображення, яке треба класифікувати.
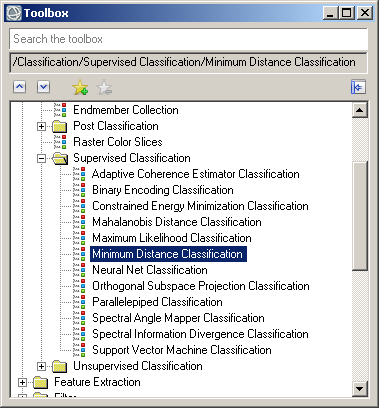
Рис. 4. Алгоритм мінімальної відстані у наборі інструментів (тулбоксі) програми ENVI
2) Після обрання знімка для класифікації з’явиться вікно Minimum Distance Parameters (рис. 5). Інтерфейс вікна налаштувань параметрів класифікації за алгоритмом мінімальної відстані дуже схожий на такий саме інтерфейс для алгоритму паралелепіпеду. В ньому також є чотири блоки:
- перелік областей обробки (блок Select Classes from Regions)
- параметри класифікації (блоки Set Max stdev from Mean та Set max Distance Error)
- налаштування збереження результату класифікації (блок Output Result to).
- налаштування збереження зображень правил (блок Output Rule Images?)
Відмінність є лише у параметрі, що завдає межи класів. Точніше, для класифікації за алгоритмом мінімальної відстані є два таких параметри – максимальне стандартне відхилення від середнього (Set max stdev from Mean) та максимальна дистанція (Set max Distance Error). Можна налаштувати один з двох параметрів, а другий залишити незаповненим. Можна налаштувати обидва параметри. У такому разі програма буде використовувати той параметр, що сильніше обмежує пошук пікселів навколо центру класу, тобто той, що менше.
Якщо ми не припускаємо наявність некласифікованих пікселів, то не треба заповнювати ці параметри (або можна поставити обидва параметри на None). Якщо некласифіковані пікселі мають бути, то треба встановити перемикач на значення Single Value або Multiple Value.
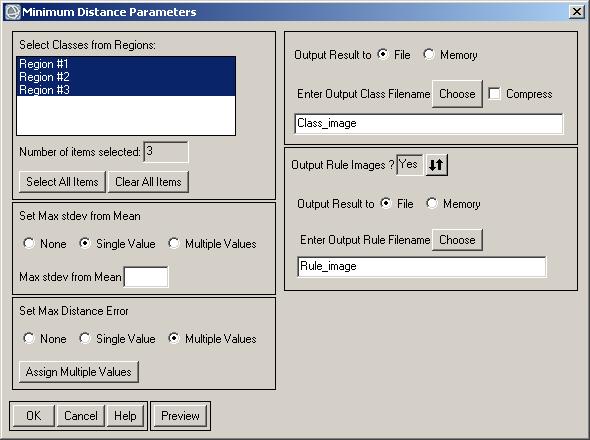
Рис. 5. Вікно налаштувань параметрів класифікації за алгоритмом мінімальної відстані
Варіант Single Value дозволяє завдати однаковий параметр класифікації для всіх класів. На рисунку 5 такий варіант обраний для параметра Set max stdev from Mean. Щоб встановити для кожного класу окреме значення обмежувального параметра, треба встановити перемикач на значення Multiple Value (на рисунку 5 він встановлений для параметра Set max Distance Error). Після цього треба натиснути кнопку Assign Multiple Values. З’явиться вікно, у якому треба ввести значення параметра для кожного класу (рис. 6).
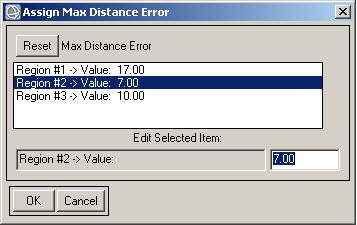
Рис. 6. Налаштування окремих значень параметру класифікації для кожного класу
3) Після того, як ми налаштували параметр класифікації, що відповідає за розподіл класів, треба обрати навчальні вибірки у блоці Select Classes from Regions. І потім налаштувати збереження результатів (карти класифікації та зображень правил).
4) На останньому рисунку наведений результат – карта класифікації.
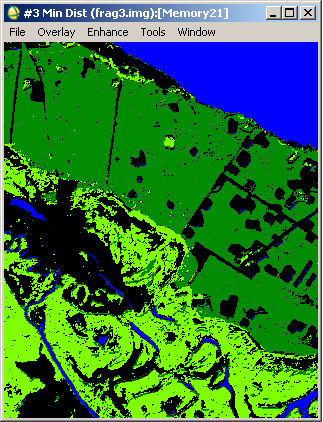
Вона має деякі дрібні помилки. Але її можна удосконалити за допомогою посткласифікаційної обробки. Про це буде один з наступних постів.