

Цим постом на нашому сайті відкривається серія постів про методи просторової статистики – галузі, що знаходиться на стику геоінформатики та статистики. Ці методи корисні при аналізі просторових даних, тобто даних з координатною прив’язкою спостережень. Якщо має значення географічна локація спостережень, або має значення розмір відстані між місцями спостережень, то це саме той випадок, у якому варто застосувати методи просторової статистики. Вони допоможуть знайти закономірності у розповсюдженні об’єктів та їх ознак, описати характер взаємозв’язків та виявити структуру просторових даних.
Спочатку ми будемо ілюструвати застосування методів просторової статистики на прикладі роботи в програмі ArcGIS. А далі ми маємо плани додати пости на цю тему з використання QGIS та R.
Теорія
Векторні шари с точковою геометрією – це дані, які доводиться обробляти практично всім користувачам ГІС. В екології та науках про Землю дуже багато таких даних почали отримувати з початком активного застосування приймачів глобальних систем позиціювання (GNSS-приймачів). Це можуть бути координати точок відбору проб, точки провадження вимірювань, місця розповсюдження деяких видів тварин та рослин та інше. В гуманітарних галузях, перш за все у соціологічних, логістичних та економіко-географічних дослідженнях, теж застосовують ГІС для аналізу точкових об’єктів. В цих галузях такими об’єктами можуть бути точки інцидентів – кримінальних подій, дорожньо-транспортних пригод, аварій на інженерних мережах та інше.
Перше питання, що виникає під час аналізу точкових даних – як об’єкти розподілені в просторі? Картографічна візуалізація об’єктів не спроможна дати однозначну відповідь. Її візуальний аналіз – це суб’єктивна процедура. Сприйняття зображення у різних дослідників може бути різним, отже і висновки будуть різними. Тому треба мати кількісний спосіб оцінки. Таким способом є критерій Кларка-Еванса (індекс найближчого сусідства).
Індекс найближчого сусідства був розроблений двома вченими – Філіпом Кларком та Френсісом Евансом, які працювали в Інституті біології людини Університету Мічигану. Вперше оприлюднений цей індекс був у 1954 році в американському часописі Ecology.
Існує безліч варіантів, як об’єкти можуть бути розташовані у географічному просторі. Але всі вони розділяються на три типи: рівномірне (дисперсне), випадкове (хаотичне) та групове (кластерне) розподілення (рис. 1). Критерій Кларка-Еванса допомагає визначити, до якого з них належить просторове розподілення об’єктів, що ми досліджуємо.

Рис. 1. Типи просторового розподілу об’єктів (зліва направо): рівномірний, випадковий та груповий
Розберемо як розраховують критерій Кларка-Еванса. Це доволі просто. Треба виконати декілька операцій. У формулах цих операцій будуть наступні позначення:
n – загальна кількість об’єктів,
r – відстань найближчого сусідства для окремого об’єкту,
S – площа території досліджування,
ρ – щільність об’єктів,
![]() – фактична (спостережувана) середня відстань найближчого сусідства,
– фактична (спостережувана) середня відстань найближчого сусідства,
![]() – очікувана (теоретична) середня відстань найближчого сусідства,
– очікувана (теоретична) середня відстань найближчого сусідства,
R – критерій Кларка-Еванса,
z – z-критерій, що використовують для перевірки статистичної значності,
![]() – стандартна похибка розрахунку очікуваної середній відстані найближчого сусідства.
– стандартна похибка розрахунку очікуваної середній відстані найближчого сусідства.
1) Спочатку для кожного об’єкта знаходять найближчого сусіда та вимірюють відстань до нього (відстань найближчого сусідства – r).
2) Далі розраховують фактичну середню відстань найближчого сусідства (![]() ) – складають відстані до найближчого сусіда кожного об’єкта та ділять на кількість об’єктів.
) – складають відстані до найближчого сусіда кожного об’єкта та ділять на кількість об’єктів.
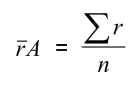
3) Потім розраховують середню відстань найближчого сусідства, що очікується при випадковому розподілі об’єктів у просторі.
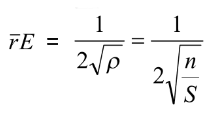
4) Далі знаходять відношення фактичної середній відстані до очікуваної середній відстані (R). Це саме і є критерій Кларка-Еванса.
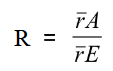
Після розрахунку критерію треба його інтерпретувати. Для цього значення критерію Кларка-Еванса порівнюють з одиницею. Якщо він дорівнює 1, то ми маємо хаотичне просторове розподілення (нульова гіпотеза для критерію Кларка-Еванса). Якщо він більший за 1 – рівномірне (дисперсне) розподілення. Якщо він менший за 1 – це групове розподілення (кластерне).
Але тут є нюанс. Наскільки великою має бути різниця з одиницею, щоб можна було казати, що критерій Кларка-Еванса відрізняється від одиниці? Щоб визначити, чи є різниця статистично значною, чи ні, треба розрахувати z-критерій:
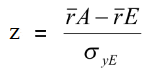
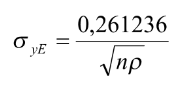
Після того, як ми розрахували z-критерій, його можна порівняти з табличним значенням для потрібного рівня статистичної значності. Але зараз це мало хто робить на практиці. Сучасні комп’ютерні програми видають точну вірогідність помилки першого роду (p- значення). Якщо вона нижче за 0,05, ми маємо статистично значну різницю між одиницею та розрахованим критерієм Кларка-Еванса.
В завершені теоретичного розділу треба сказати, що критерій Кларка-Еванса може бути розрахований не тільки для точкових об’єктів, але також для полігональних або полілінійних об’єктів. У такому разі для розрахунків використають координати центроїдів об’єктів.
Практика
Розглянемо практику застосування критерію Кларка-Еванса в програмі ArcGIS.
Розберемо як працювати з критерієм Кларка-Еванса на наступному прикладі. Наші дані для аналізу – це населені пункти у п’яти районах Бєлгородської області – Бєлгородському, Борисовському, Корочанському, Шебекінському та Яковлівському (рис. 2). На цій території розташована Бєлгородська агломерація та її околиці. Треба визначити, як розподілені у просторі населені пункти.

Рис. 2. Розташування населених пунктів у п’яти районах Бєлгородської області
1) Оберіть у Тулбоксі (ArcToolbox) команду Spatial Statistic Tools → Analyzing Patterns → Average Nearest Neighbor (рис. 3).
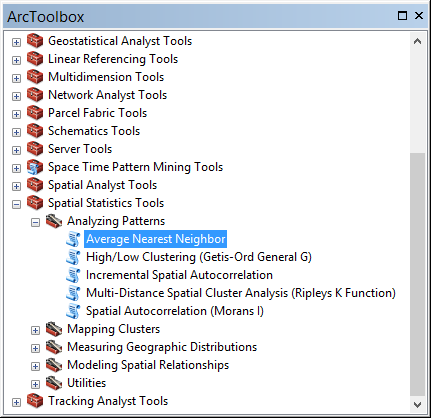
Рис. 3. Вибір команди в наборі інструментів ArcToolbox
2) З’явиться вікно Average Nearest Neighbor (рис. 4), у якому треба налаштувати параметри процедури.
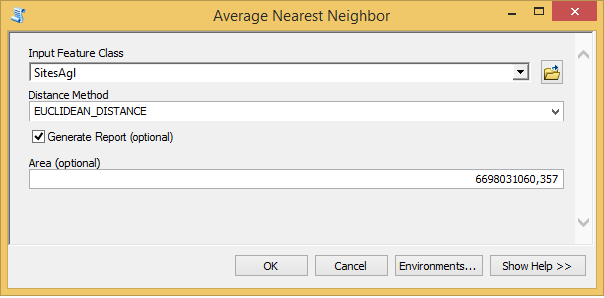
Рис. 4. Вікно налаштувань параметрів розрахунку критерію Кларка-Еванса
3) У полі Input Feature Class вкажіть векторний шар з даними, що підлягають аналізу.
4) У полі Distance Method оберіть метод визначення дистанції. Є два варіанти – евклідова дистанція та манхеттенська дистанція (рис. 2).
Евклідова дистанція – це звичайна відстань, яка вимірюється за прямою лінією, що з’єднує об’єкти. У нашому прикладі треба обрати саме її.
Манхеттенська дистанція – це сума катетів прямокутного трикутника, гіпотенуза якого є пряма лінія, що з’єднує об’єкти. Інакше кажучи, це сума абсолютних різниць координат за двома осями. З такою дистанцію ми теж зустрічаємося у повсякденному житті, наприклад коли ходимо міськими вулицями. В такому разі ми часто не можемо іти прямо, бо упремося у стіну будинку. Треба обійти будівлю, спочатку йти до перехрестя та потім на ньому зробити поворот в необхідному напрямку. Тому друга назва цієї дистанції – дистанція міського кварталу. Назва ж манхеттенська дистанція походить від району Нью-Йорку Манхеттен, що має прямокутне планування вулиць.
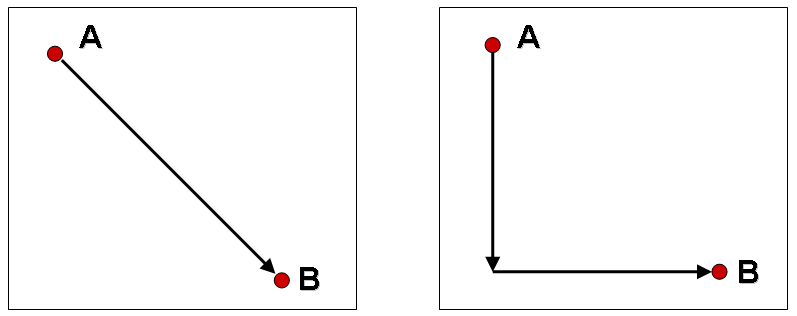
Рис. 5. Евклідова дистанція (ліворуч) та манхеттенська (праворуч) дистанція
5) У полі Area вкажіть площу. Її треба вказувати в тих самих одиницях, що має фрейм даних. У нашому прикладі це метри. Площа території п’яти районів з нашого прикладу дорівнює 6 698 031 060,357 метра.
Площа – це не обов’язкове поле для заповнення. За замовчуванням воно пусте. А площа приймається рівною площі прямокутника, що проведений через крайні точки. Коли форма території дослідження наближена до прямокутника, можна використати варіант за замовчанням. В іншому разі треба вказувати площу вручну, щоб уникнути помилок при розрахунках.
На рисунку 5 праворуч наведений приклад, коли використання площі за замовчуванням призведе до помилкових результатів. Замість рівномірного розподілу, ми визначимо випадковий розподіл. А на рисунку 5 ліворуч прилад, коли в обох варіантах буде однаковий результат – рівномірний розподіл.

Рис. 6. Ситуація, коли використання площі за замовчанням не приведе до помилок (ліворуч) та приведе до помилок (праворуч)
6) Вкажіть чи створювати графічний звіт чи ні (вимикач Generate Report). Результати розрахунків програма за замовчуванням показує в кількісному вигляді у повідомленні, що з’являється після завершення процедури. Але вона може також створити графічний звіт у формі html-файлу. У ньому містяться не тільки результати розрахунків, але і їх інтерпретація. Так на рисунку 7 наведений графічний звіт для нашого прикладу. В ньому рамкою позначений тип просторового розподілу, що мають наші дані. Це рівномірне (дисперсне) розподілення. І це очікуваний результат. Бєлгородська агломерація насправді є територією, де населенні пункти розподілені рівномірно.
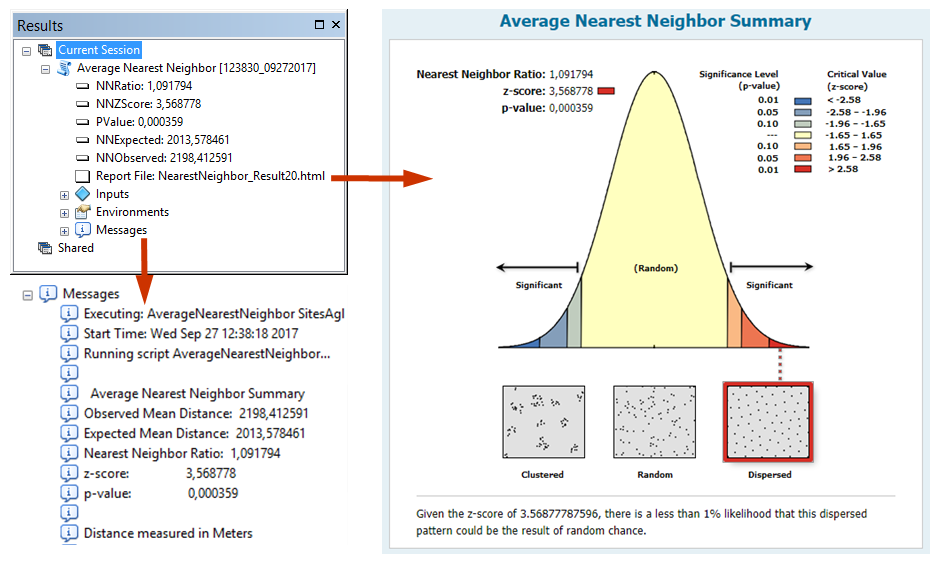
Рис. 7. Повідомлення з результатами та графічний звіт для аналізу найближчого сусідства
Треба мати на увазі, що коли програма ArcGIS робить графічний звіт, вона відхиляє нульову гіпотезу при p<0,05. Якщо Вам необхідна більш жорстка перевірка статистичних гіпотез (наприклад для відхилення нульової гіпотези треба p<0,01 або p<0,001), то треба самостійно інтерпретувати результати на основі аналізу кількісних результатів.
Розберемо кількісні результати для нашого прикладу. Ми бачимо, що середня відстань найближчого сусідства рівна 2198,41 метра. До речі, що це значить на побутовому рівні? Якщо приймати швидкість пішоходу за шість кілометрів на годину, то на території з нашого прикладу він у середньому дійде з центру одного населеного пункту до іншого приблизно за 22 хвилини. Звісно, це коли там є прямий асфальтований шлях, або погода та стан місцевості не заважають пересуванню пішохода.
При випадковому розподілі об’єктів на такій площі, яку має досліджувана територія, середня відстань найближчого сусідства має дорівнювати 2013,58 метрам. Це більш ніж фактична відстань. Таким чином, коли ми поділимо фактичну відстань на очікувану, то отримаємо критерій Кларка-Еванса рівний 1,09.
Критерій Кларка-Еванса більше ніж одиниця. Але чи достатня ця різниця, щоб стверджувати, що населенні пункти розподілені рівномірно? Для z-теста p-значення рівне 0,0004. Тобто імовірність того, що ми помилково відхилимо нульову гіпотезу (випадковий розподіл) дуже маленька. Тому ми відхиляємо нульову гіпотезу, та приймаємо альтернативну – населенні пункти розподілені рівномірно.




Здорово Паша! Помню, как мы с этим разбирались
Я и сейчас еще продолжаю копаться в этой теме