

Під час налаштування процедури розрахунку багатьох критеріїв просторової статистики треба вказувати поріг дистанції. Він використовується, щоб знайти сусідів кожного об’єкту та визначити просторові ваги, що показують вплив об’єктів один на одного. Ці просторові ваги є одною зі змінних у формулах розрахунку критеріїв просторової статистики.
Теорія
Від значення порогу дистанції дуже залежить результат розрахунку статистичних критеріїв. Тому завжди стоїть питання – як визначити його оптимальний розмір? Тут спочатку треба з’ясувати для себе, яким є, власне, оптимальний розмір. Коли ми використовуємо методи просторової статистики, нас звичайно цікавить наявність просторових закономірностей. Тобто ми намагаємося знайти ознаки групового розподілення характеристик об’єктів, які досліджуємо. А якщо розподіл у просторі є випадковим або рівномірним, то це вказує на ймовірну відсутність просторових закономірностей. Таким чином, оптимальним порогом дистанції для пошуку сусідів та визначення просторових ваг є та відстань, на якій тенденція до групового розподілу є найбільш вираженою.
Але як все ж таки прийняти правильне рішення, як визначити оптимальне значення порогу дистанції? Тут є два варіанти. Варіант перший – добре знати об’єкт та територію дослідження, розуміти сутність процесів, що зумовлюють формування просторових закономірностей. Опора на свій дослідницький досвід дозволить прийняти правильне рішення.
Якщо дослідницького досвіду не вистачає, то допоможе другий варіант – оцінити просторову автокореляцію (на підставі критерію Морана І) зі всіма можливими відстанями Для цього обирають якесь мінімальне значення відстані та роблять розрахунок для нього. Потім крок за кроком збільшують відстань на якусь величину і роблять нові розрахунки. Тому цю процедуру називають покрокова оцінка просторової автокореляції на різних дистанціях, або скорочено – покрокова просторова автокореляція. Та відстань, на якій статистична значність позитивної автокореляції найбільша, і є оптимальним порогом дистанції.
Для критерію Морана I статистична значність оцінюється за допомогою z-критерію. Чім він більший, тим більше статистична значність просторової кластеризації, тобто є більш вираженим груповий розподіл. А максимальні негативні значення z- критерію вказують на найбільш значний рівномірний просторовий розподіл.
Результати покрокової оцінки просторової автокореляції звичайно відображують у вигляді графіку z-критерію. На цьому графіку по осі X стоять значення відстані, по осі Y – розмір z-критерію. Пік на цьому графіку вказує на відстань з найбільш вираженою кластеризацією. У деяких випадках крива значень z- критерію може мати декілька піків. Це значить, що на різних рівнях масштабу існують різни просторові закономірності. Тому призначення покрокової оцінки просторової автокореляції не обмежується підбором оптимального радіусу пошуку. Вона ще дозволяє аналізувати, як змінюються просторові закономірності зі зміною масштабу дослідження.
Розрахунок критерію Морана I за всіма можливими радіусами пошуку може дати багато цікавого для аналізу матеріалу. Але він займає багато часу. Та й «конвеєрне» повторення однакових операцій стомлює. Тому зараз існують програмні рішення, що дозволяють автоматизувати цей процес, звести його до однієї операції. У цьому пості ми розберемо, як це зроблено у програмі ArcGIS.
Практика
Покрокову оцінку просторової автокореляції ми розберемо на прикладі з посту про критерій Морана І. В ньому аналізувалася частка мешканців деяких районів Бєлгородської області, що за даними перепису населення 2002 року народилися за межами Бєлгородської області (рис. 1). Треба встановити, на якій відстані просторова автокореляція найбільш значна (мається на увазі статистична значимість).
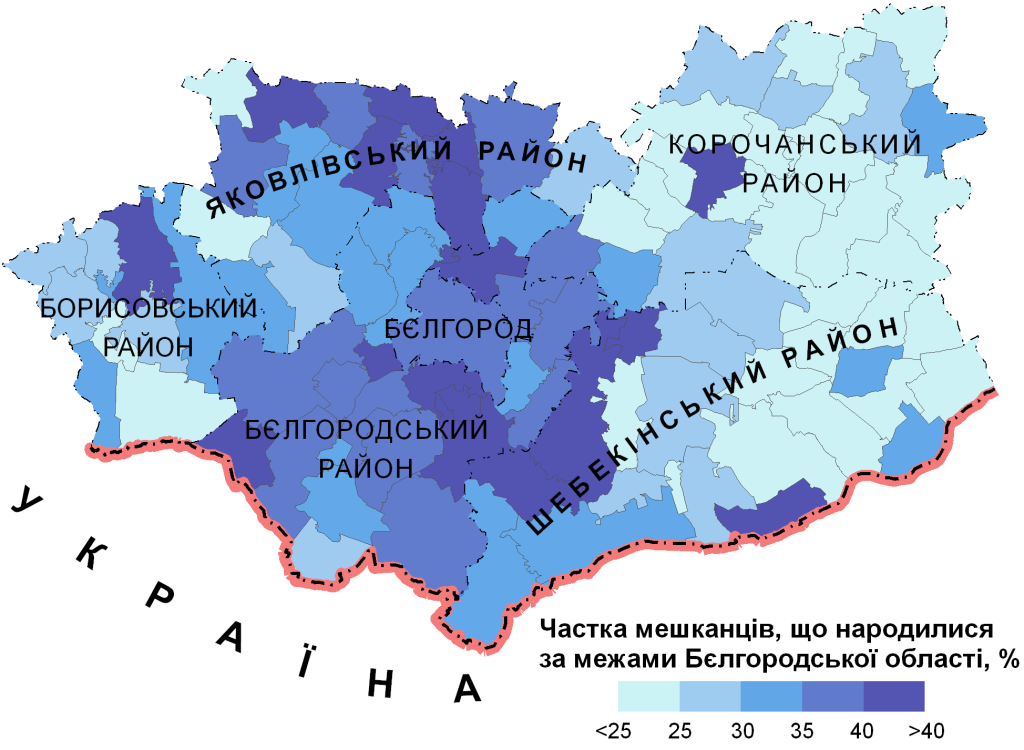
Рис.1. Частка народжених за межами Бєлгородської області
1) Щоб запустити процес покрокового розрахунку загального критерію Морана I, треба в Тулбоксі програми ArcGIS обрати команду Spatial Statistic Tools → Analyzing Patterns →Incremental Spatial Autocorrelation (рис.2).
Рис. 2. Інструмент для покрокового розрахунку критерію Морана І в ArcToolbox
2) Після запуску інструменту з’явиться вікно налаштувань, у якому треба налаштувати дев’ять параметрів. Три перших (якщо лічити згори вниз) з них є обов’язковими для заповнення. Інші параметри можна залишити незаповненими або за замовчанням (рис. 3).
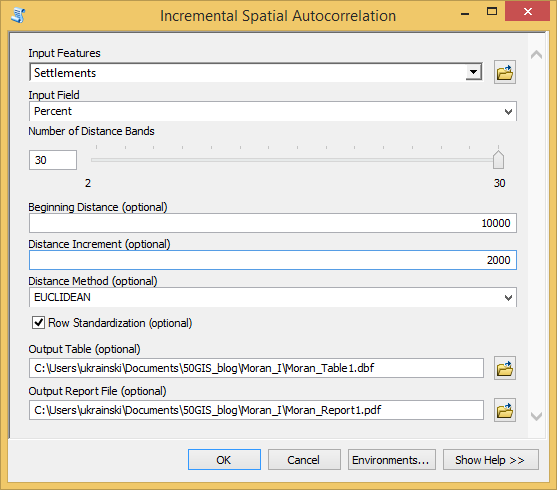
Рис.3. Вікно налаштувань процедури покрокової просторової автокореляції
3) Перші два обов’язкових параметри – векторний шар для аналізу та стовпчик з таблиці атрибутів цього шару, який містить показник для аналізу. Векторний шар треба вказати в полі Input Features. Після цього в списку Input Field з’являться атрибути обраного шару. З них треба обрати показник, для якого ми будемо розраховувати критерій Морана І.
4) Третій обов’язковий параметр – це кількість дистанцій, для яких буде розраховуватися критерій Морана І (Number of Distance Bands). Вона може бути від 2 до 30. Точне значення можна встановити за допомогою бігунка. Також можна ввести його з клавіатури у рядок вводу, що знаходиться ліворуч від бігунка.
5) Далі можна (але не обов’язково) встановити початкову дистанцію (Beginning Distance) та розмір зростання дистанції (Distance Increment). За замовчанням ці параметри не встановлені. Програма сама визначає їх згідно з розмірами території, що охоплює векторний шар, та розмірами об’єктів у цьому шарі.
У нашому прикладі (рис. 3) вручну встановлені наступні значення: початкова дистанція 10000 метрів, зростання дистанції – 2000 метрів.
6) Зі списку Distance Method можна обрати спосіб розрахунку дистанції. Є два варіанти: евклідова дистанція (стоїть за замовчанням) та манхеттенська дистанція. Чим вони відрізняються, можна прочитати тут.
7) Вимикач Row Standardization налаштовую стандартизацію просторових ваг. За замовчанням стандартизація не ввімкнута. Це значить, що для розрахунку критерію Морана І використовуватимуться абсолютні (не стандартизовані) значення просторових ваг. Якщо для Row Standardization поставити галочку, то замість абсолютних значень для розрахунку будуть братися стандартизовані значення, тобто поділені на суму просторових ваг.
8) Останні параметри, що можна налаштувати – це способи збереження результатів. За замовчанням результат не зберігається. Його можна переглянути лише в поточному сеансі роботи ArcGIS, скориставшись пунктом меню Geoprocessing.
Додатково можна зберегти результат у вигляді звіту в форматі pdf та у вигляді таблиці в форматі dbf. Для цього в полях Output Table та Output Report File треба вказати місце збереження та ім’я файлів.
9) Після того, як всі параметри процесу налаштовані, треба натиснути кнопку OK і можна переходити до аналізу результатів.
10) Щоб переглянути результати, треба в меню ArcGIS обрати команду Geoprocessing→Results. Після цього відкриється вікно з інформаційними повідомленнями, що описують виконану операцію та її результати (рис.4).
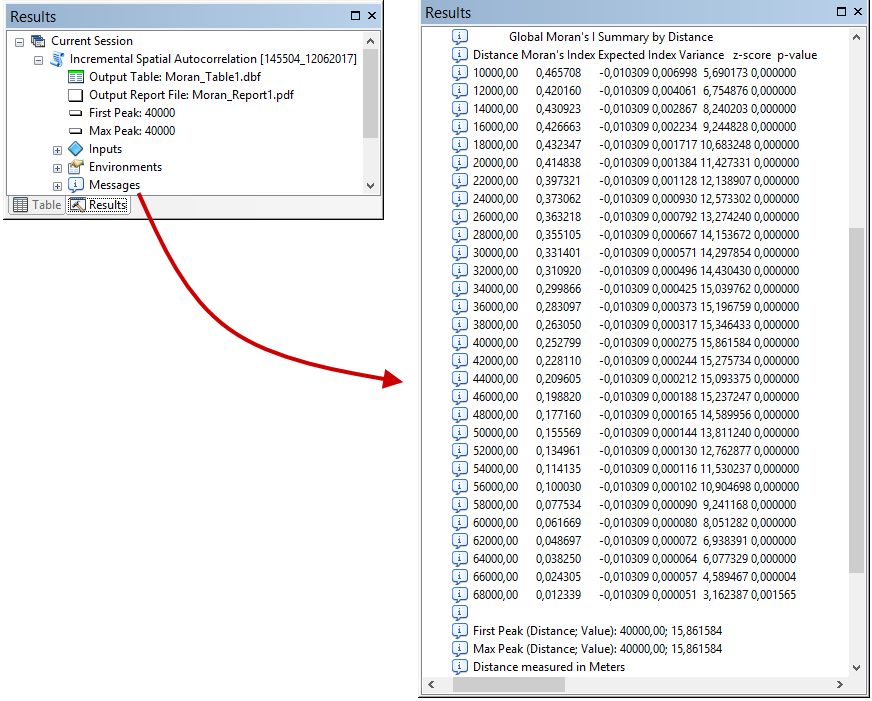
Рис. 4. Інформаційні повідомлення з результатами покрокового розрахунку критерію Морана І
В інформаційних повідомленнях перш за все вказується відстань, на якій виявлений перший пік (First Peak) значення z-критерію. Потім вказується дистанція, на якій z-критерій сягає найбільшого значення (Max Peak). У нашому випадки обидва пики збігаються і фіксуються на дистанції 40000 метрів. Щоб проаналізувати результати детальніше, потрібно в інформаційних повідомленнях розгорнути пункт Messages (рис. 4). У цьому пункті для кожної відстані показане фактичне значення критерію Морана I, очікуване значення критерію Морана I, z-критерій та р-значення.
11) Якщо Ви встановили опцію збереження результатів у вигляді таблиці, то програма запише dbf-файл то додасть його у таблицю змісту. Цю таблицю можна відкрити та переглянути. На рисунку 5 ми бачимо, що в цій таблиці ті ж самі результати, що й в пункту Messages інформаційних повідомлень (рис. 4).
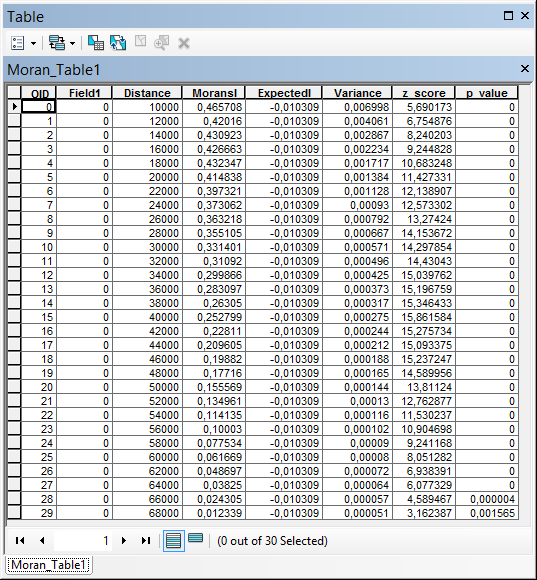
Рис. 5. Таблиця з результатами покрокового розрахунку індексу Морана І
12) Якщо Ви встановили опцію створення звіту, то програма створить файл у форматі pdf. Крім даних, що є в інформаційних повідомленнях та dbf-таблиці, в цьому файлі є графік значень z-критерію (рис.6).
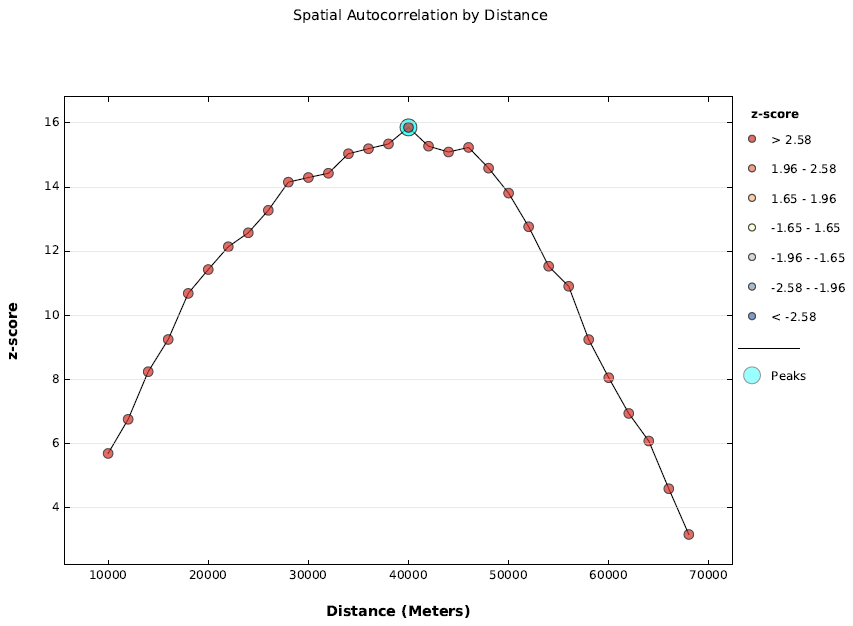
Рис.6. Графік залежності z- критерію від дистанції
Колір точок на графіку позначає статистичну значимість. Якій є зв’язок між значеннями z- критерію та р- значеннями, можна прочитати тут. Точки жовтого кольору – це статистично незначні значення, які вказують на тенденцію до випадкового розподілу у просторі. Точки відтінків синього кольору – це статистично значна тенденція до рівномірного розподілу. Точки відтінків червоного кольору – це статистично значна тенденція до групового розподілу.
В нашому випадку на всіх дистанція ми маємо статистично значне групування. З ростом дистанції спочатку z-значення ростуть, а після 40000 метрів – починають зменшуватися. Цей пік на графіку позначений блакитним гало.
Чому при відстані 40 кілометрів тенденція до групування значень у просторі найбільш виражена – сказати важко. Відповідь на це питання вимагає окремого дослідження. Але впадає в очі, що розмір відстані з найбільш значним групуванням є близьким до середньої ширини адміністративного району. Можливо тут має місце посередній вплив конфігурації адміністративного поділу на соціально-демографічні процеси.


Методы пространственной статистики универсальны. Они подходят для любых пространственных данных, и, теоретически, могут применяться в любой отрасли. Но пространственная статистика – это весьма молодая отрасль статистики, поэтому она еще не везде укоренилась. Более-менее активно она стала развиваться только с 70-х годов. Некоторые методы были разработаны совсем недавно, в 90-е годы.
Сейчас чаще всего пространственная статистика применяется в экономической, социальной и политической географии и смежных с ней отраслях. Применяют как на внутригородском уровне, так и на уровне региона и страны в целом.
Типичные примеры изучения пространственной автокорреляции из практики отечественных гуманитариев:
goo.gl/BmCwGK
goo.gl/CjrxCt
goo.gl/1Hgck7
goo.gl/D5agi9
Вторая отрасль, где используют методы пространственной статистики – это экология. Здесь у нас подобные работы встречаются реже (за рубежом пространственная статистика чаще используется в экологии). Например:
goo.gl/3iymYZ
goo.gl/nsCqGA
Обычно использованием общего критерия Морана I не ограничиваются. После обнаружения положительной автокорреляции начинают выделять пространственные кластеры с помощью локального критерия Морана I.
Дякую за статтю
Які реальні (в науці, бізнесі) приклади використання алгоритму Morans’ I?