

В минулому пості з теми просторової статистики ми розібрали як визначити характер розподілу об’єктів у просторі. Але крім розподілення самих об’єктів, цікавим є також просторове розподілення ознак об’єктів. Адже між одними й тими ж об’єктами одні ознаки можуть бути розподілені рівномірно, а інші груповим або хаотичним зразком. Визначається це за допомогою критерію Морана I (I – це літера, а не римська цифра 1).
Теорія
Критерій був розроблений австралійським статистиком Патріком Альфредом Пірсом Мораном (також відомий як Пет Моран) в кінці 40-х років XX сторіччя. У ті роки Пет Моран працював у Інституті статистики університету Оксфорда на посаді старшого наукового співробітника. Перша наукова публікація, в якій для оцінки просторової автокореляції був запропонований критерій Морана, вийшла в 1950 році в англійському часописі Biometrika.
Спочатку трохи термінології. А точніше розберемо зміст лише одного терміну – просторової автокореляції. Почнемо зі «звичайної» кореляції. Кореляція або кореляційна залежність – це взаємозв’язок між двома (або більше) величинами, коли зміни в одній величині супроводжуються змінами в іншій величини. Автокореляція це такий же зв’язок, але тільки однієї величини самої з собою. Таке може бути, коли вимірювання розподілені у часі або у просторі. В цьому разі може існувати взаємозв’язок між вимірюваннями, що зроблені з різною відстанню у часі або у просторі. У першому випадку це буде автокореляція у часі, а у другому – просторова автокореляція.
Критерій Морана I – це коефіцієнт просторової автокореляції. Як і «звичайний» коефіцієнт кореляції, він може змінюватися від -1 до 1. Як критерій Морана I пов’язан з характером просторового розподілу значень? Всі можливі розподіли значень ознак у просторі можна звести до трьох форм (рис. 1):
- випадковий (хаотичний) розподіл значень,
- однорідний (рівномірний, дисперсійний) розподіл значень,
- груповий (кластеризований) розподіл значень.
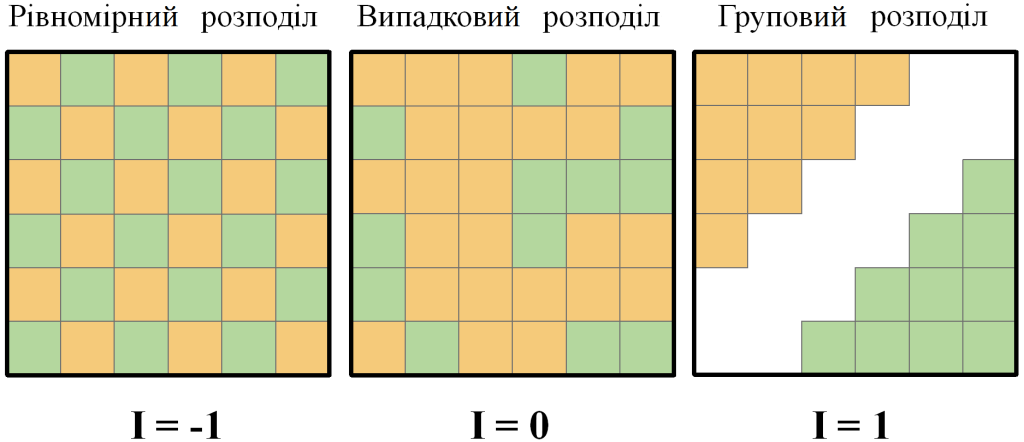
Рис. 1. Форми розподілу значень у просторі
Значення критерію, що очікується для випадкового розподілу значень, приблизно дорівнює 0. У більшості випадків його різниця з нулем настільки мала, що не буде великою помилкою сказати, що при випадковому розподілі критерій Морана І дорівнює нулю.
Якщо критерій Морана І наближений до нуля, то просторова автокореляції відсутня, а значення розподілені у просторі випадковим чином. Якщо він статистично значно більше нуля, то є позитивна просторова автокореляція, а значення розподілені у просторі груповим чином. У разі, коли критерій Морана І статистично значно менший нуля, то ми маємо негативну просторову автокореляцію, а значення розподілені у просторі рівномірно.
Тепер розберемо, як визначити критерій Морана I. Це простий, але доволі трудомісткий процес, особливо якщо у нас багато об’єктів. Але сучасне програмне забезпечення дозволяє зробити це практично моментально.
Формула розрахунку критерію Морана І має наступний вигляд:
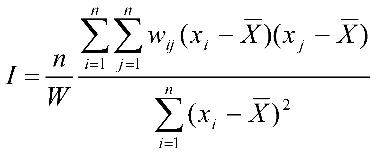
У цій формулі I – критерій Морана,
n – кількість об’єктів,
![]() – середнє значення атрибуту,
– середнє значення атрибуту,
![]() – значення ознаки для об’єктів i та j,
– значення ознаки для об’єктів i та j,
w – просторова вага для пари об’єктів,
W – сума просторових ваг.
Розберемо зміст цієї формули. Розрахунок виконується у декілька кроків:
1) Спочатку треба вираховувати середнє значення ознаки (![]() ).
).
2) Потім для кожного об’єкту вираховують відхилення значення ознаки від середньої. Тобто вираховують різницю між його значенням ознаки та середнім значенням ознаки (![]() ).
).
3) Наступним кроком всі відхилення від середнього підносять до другої степені та вираховують суму цих квадратів:
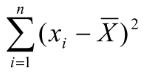
4) Для кожної пари об’єктів встановлюють просторові ваги (w). Вони показують, наскільки великим є взаємний вплив між об’єктами. Існують різни способи визначення просторових ваг. Частіше за все їх розраховують на основі відстані між об’єктами, у найпростішому випадку як зворотну відстань (тобто одиниця, що поділена на відстань).
5) Вираховують суму просторових ваг (W):
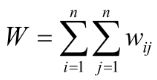
6) Кількість об’єктів ділять на суму просторових ваг:
![]()
7) Далі у кожній парі об’єктів перемножують відхилення від середнього та просторову вагу:
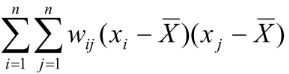
8) На фінальному кроці результат сьомого кроку поділяють на результат третього кроку та перемножують на результат шостого кроку. І ми нарешті отримуємо фактичне значення критерію Морана І, яке потом треба порівняти з очікуваним значенням критерію Морана І.
Очікуване значення критерію Морана І, що має бути при випадковому розподілі значень, вираховують за наступною формулою:
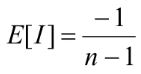
У цій формулі E[I] – очікуване значення критерію Морана, n – кількість об’єктів. З цієї формули ми бачимо, що чим більше у нас об’єктів, тим ближче значення E[I] до нуля.
Порівнюючи значення І та Е[I], треба встановити, чи є статистично значною різниця між ними. Оцінка статистичної значності робиться за допомогою z-критерію та вимагає ще більше розрахунків, ніж у наведених вище формулах. Тому ми їх опустимо. Але деталі розрахунків можна прочитати тут та тут.
Практика
Розберемо роботу з критерієм Морана І в програмі ArcGIS на наступному прикладі. Візьмемо векторний шар з муніципалітетами навколо Бєлгорода, приблизно в межах Бєлгородської агломерації (рис. 2). В атрибутах цього шару є поле з відсотком мешканців, що народилися за межами Бєлгородської області. Цю інформацію взято з бази мікроданих перепису населення 2002 року. Нам треба визначити, як розподілено це значення.
Коли ми візуалізуємо наші просторові дані, то вже можна зробити висновки про те, яке розподілення мають значення. Але це будуть суб’єктивні висновки. Окрім того, сприйняття картографічної візуалізації буде змінюватися в залежності від того, які градації ознаки та яку кольорову шкалу ми використаємо. Тому, щоб дати об’єктивну оцінку, треба використати кількісні способи аналізу.
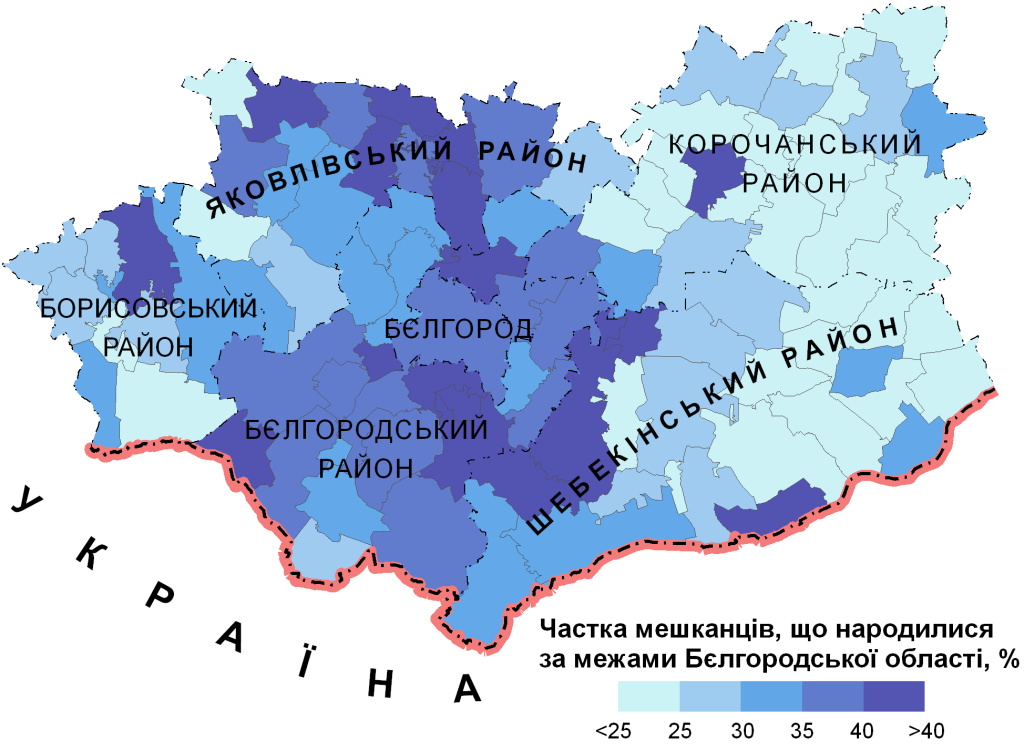
Рис. 2. Частка народжених за межами Бєлгородської області
1) Щоб запустити розрахунок критерію Морана І оберіть в ArcToolbox (рис. 3) команду Spatial Statistic Tools → Analyzing Patterns → Spatial Autocorrelation (Morans I). З’явиться вікно Spatial Autocorrelation (Morans I), у якому треба налаштувати параметри розрахунку (рис. 4).
Рис. 3. Інструмент для розрахунку критерію Морана І в ArcToolbox
2) У списку Input Feature Class укажіть векторний шар, що містить інформацію для аналізу.
3) У списку Input Field укажіть поле (стовпчик) з таблиці атрибутів, для якого треба розрахувати критерій Морана І.
4) Позначте опцію Display Output Graphically, щоб отримати графічний звіт з результатами розрахунку.
5) У списки Conceptualization of Spatial Relationships оберіть спосіб концептуалізації просторових відношень. Інакше кажучи, це – спосіб розрахунку просторових ваг. Це важливий параметр, бо результат розрахунку дуже залежить від них.
ArcGIS пропонує обрати один із варіантів:
Inverse Distance – зворотна відстань,
Inverse Distance Squared – зворотна відстань в квадраті,
Fixed Distance Band – фіксована відстань,
Zone of Indifference – зона індиферентності,
Polygon Contiguity (First Order) – суміжність полігонів (першого порядку),
Get Spatial Weight From File – завантажити просторові ваги з файлу.
Щоб правильно обрати спосіб концептуалізації просторових відношень, треба добре знати територію та явище, що досліджуються. Треба уявляти, як залежить вплив одного об’єкта на інший від характеру взаємного розташування та дистанції між ними.
Особливостям способів концептуалізації просторових відношень буде присвячений окремий пост. За замовчуванням в ArcGIS стоїть варіант Inverse Distance. Цей варіант ми й будемо використати у нашому прикладі.
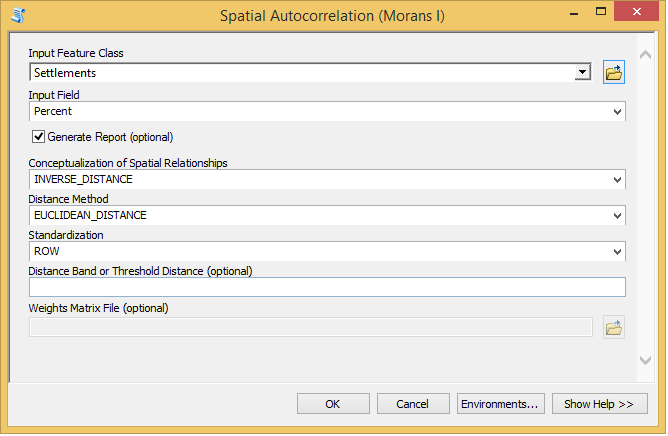
Рис. 4. Вікно налаштувань розрахунку критерію Морана І
6) У списку Distance Method оберіть метод розрахунку відстані між об’єктами. Тут пропонуються два варіанти: евклідова дистанція та манхеттенська дистанція. За замовчуванням стоїть евклідова дистанція. Для нашого приклада ми будемо використати саме її.
7) У списку Standardization оберіть спосіб стандартизації значень просторових ваг. Тут пропонуються два варіанти – None та Row. За замовчуванням стоїть варіант None, тобто не робити стандартизацію. Це значить, що для розрахунку будуть братися абсолютні значення просторових ваг. Якщо обрати варіант Row, то кожне значення просторової ваги буде поділено на суму просторових ваг. Перераховані значення ваг будуть коливатися від 0 до 1. Нормалізацію рекомендують робити, коли згідно з обраним способом розрахунку просторових ваг, у різних об’єктів відрізняється кількість сусідів.
8) Значення в рядку Distance Band or Threshold Distance (optional) використовується для визначення кількості сусідів, що будуть братися для розрахунку критерію Морана І. Це радіус пошуку сусідів. Він може бути незаповненим (за замовчуванням), дорівнювати 0, або бути більшим за 0. Для кожного способу концептуалізації просторових відношень ці значення впливають на кількість сусідів своїм чином. В нашому прикладі ми залишаємо значення за замовчуванням.
Якщо ми використаємо зворотну відстань при розрахунки просторових ваг, то при незаповненому значенні програма сама знайде таку дистанцію, щоб у кожного об’єкта був би щонайменше один сусід. При нулі всі існуючі об’єкти будуть сусідами для окремого об’єкта. При значенні більшому ніж нуль, сусідами будуть лише об’єкті, що попадають в межі, окреслені радіусом пошуку.
9) Коли налаштовані всі параметри розрахунку, треба натиснути в вікні Spatial Autocorrelation (Morans I) кнопку OK. Ми отримаємо графічний звіт у форматі html (рис. 5).

Рис.5. Графічний звіт із результатами оцінки просторової автокореляції
Проінтерпретуємо результат. Ми маємо для наших даних фактичне значення загального індексу Морана I = 0,47. Для випадкового розподілу очікується значення загального індексу Морана E[I] = -0,01. Імовірність помилки першого роду (p-value), тобто того, що знайдемо закономірність, яка не існує, менше ніж 0,05. Це значить, що фактичне та очікуване значення критерію Морана статистично значно відрізняються. Таким чином, ми маємо позитивну просторову автокореляцію ознаки. Частка населення, що народилось у межах Бєлгородської області, має груповий просторовий розподіл. А от чому так склалося, це тема для окремого дослідження. Скажемо лише, що наявна картина пов’язана з різницею у міграційної привабливості муніципалітетів. І в значній мірі вона склалася такою у 90-ті роки XX сторіччя.



