

Якщо ми застосовуємо будь-який алгоритм класифікації для дешифрування космічного знімка, нас завжди цікавить точність результату. Найпростіший спосіб її оцінки — це візуальна оцінка. Коли ми порівнюємо космічний знімок із результатом його класифікації, то можемо побачити помилки та приблизно оцінити їхні розмір. Але якщо нам треба серйозна точність оцінювання, то не обійтися без застосування кількісних методів оцінки.
Теорія
У якості кількісного методу для характеристики точності класифікації зазвичай використовують матрицю помилок. Це таблиця, що показує відповідність між результатом класифікації та еталоном. Тобто для створення матриці помилок треба мати будь-який еталон. Таким еталоном може бути картографічна інформація, результат ручної векторизації космічного знімка, дані наземного обстеження, що зафіксовані за допомогою GPS-навігатора.
Умовний приклад матриці помилок показує таблиця 1. Розберемо її зміст. Стовпчики таблиці 1 — це класи еталона, а рядки таблиці — це класи зображення класифікації, точність якої ми оцінюємо. Чарунки таблиці показують кількість пікселів для всіх імовірних співвідношень еталона та зображення класифікації.
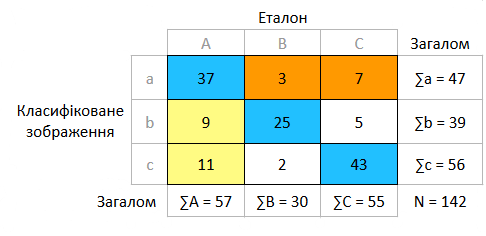
Яку інформацію ми маємо з матриці помилок?
По-перше, необхідно звернути увагу на головну діагональ матриці. У таблиці 1 вона позначена блакитним кольором. Чарунки цієї діагоналі містять кількість правильно розпізнаних пікселів. Якщо суму пікселів цих чарунок поділити на загальну кількість пікселів, то ми отримаємо загальну точність класифікації (overall accuracy, OvAc). Для матриці помилок, що наведена в таблиці 1, цей показник буде дорівнювати:
OvAc = ( aA + bB + cC ) / N = ( 37 + 25 + 43 ) / 142 ≈ 0,74
Ще один показник точностi — каппа-коефіцієнт. Він може приймати значення від 0 до 1. Якщо каппа-коефіцієнт дорівнює нулю, то ніякої відповідності між зображенням класифікації та еталоном взагалі не існує. Якщо каппа-коефіцієнт рівний 1, то зображення класифікації й еталон повністю тотожні одне до одного. Тобто чим більше каппа-коефіцієнт, тим точніше класифікація.
Окрім загальної точності, варто оцінити точність дешифрування кожного класу. Для цього треба звернути увагу на недіагональні чарунки в стовпчиках, а також на недіагональні чарунки в рядках. У цих чарунках містяться помилки класифікації, тобто випадки, коли еталон та зображення класифікації не збігаються. Є два типи цих випадків, тобто помилок: помилки пропускання (помилки омісії, омісія, omission) та помилки приписування (помилки комісії, комісія, commission).
Помилки приписування будь-якого класу виникають, коли процедура класифікації зараховує до класу пикселі, що насправді до нього не належать. Кількість пикселів, що були помилково приписані до класу, у таблиці 1 стоїть у чарунках стовпчика класу вище та нижче головної діагоналі. Для класу А помилки приписування позначені там блідо-жовтим кольором. Сума цих чарунок — це абсолютне значення комісії класу. А якщо поділити цю суму на загальну кількість пікселів класу в еталоні, то ми отримаємо відносну помилку комісії (Сom):
Сom = ( bA + cA ) / ∑A = ( 9 + 11 ) / 57 ≈ 0,35
Розмір помилок приписування також характеризують таким показником як Producer’s accuracy («точність виробника», PrAc). Це кількість правильно впізнаних пікселів класу, що поділена на загальну кількість пікселів класу в еталоні. Для класу А з таблиці 1:
PrAc = aA / ∑A = 37 / 57 ≈ 0,65
Значення Сom і PrAc пов’язані:
PrAc = 1 – Сom
Помилки пропускання будь-якого класу виникають коли пікселі, що насправді належать одному класу, зараховуються до інших класів. У таблиці помилок кількість пікселів класу, що були пропущені, стоять у чарунках рядка класу лівіше та правіше головної діагоналі. Помилки пропускання класу А позначені жовтогарячим кольором. Сума цих чарунок — це абсолютне значення омісії класу. А якщо поділити цю суму на загальну кількість пікселів класу зображення класифікації, то отримаємо відносну помилку омісії (Om):
Om = ( aB + aC ) / ∑a = ( 3 + 7 ) / 47 ≈ 0,21
Розмір помилок пропускання також характеризують таким показником як User’s accuracy («точність користувача», UsAc). Це кількість правильно впізнаних пікселів класу, що поділена на загальну кількість пікселів класу в зображенні класифікації. Для класу А з таблиці 1 цей показник дорівнює:
UsAc = aA / ∑a = 37 / 47 ≈ 0,79
Значення Om і UsAc пов’язані:
UsAc = 1 – Om
Як ми бачимо, існує декілька показників точності класифікації. Тому постає питання, які показники треба наводити щоби правильно охарактеризувати точність класифікації? Щонайменше треба вказувати загальну точність класифікації або каппа-коефіцієнт. Але це буде неповна характеристика. Краще також вказувати й розмір помилок комісії та омісії. Бо загальна точність класифікації сама собою може вводити в оману. Може так статися, що загальна точність буде достатньо високою, але окремий клас або декілька класів при цьому будуть мати багато помилок. І якщо точність саме цих класів найбільш важлива для користувача, то результат класифікації можна вважати невдалим, незважаючи на його високу загальну точність. Так само взяті окремо значення точності користувача та виробника не відображають якість загальної класифікації.
Практика
Тепер розберемо, як саме розрахувати та як інтерпретувати матрицю помилок у програмі ENVI. Для цього є інструмент Confusion Matrix. Він створює матрицю помилок та зображення помилок у кожному класі. Також він розраховує оцінки точності класифікації (загальну точність класифікації, каппа-коефіцієнт, помилки комісії та омісії для кожного класу).
На рисунку 1, зліва, фрагмент космічного знімку Landsat 5 TM за 16 вересня 2009 року. Він охоплює територію навколо заплави Сіверского Дінця, що знаходиться на південь від села Мохнач у Зміївському районі Харківської області. Для відображенні знімку (рис.1) використана комбінація каналів 4:5:3. У ній для рослинності характерними є жовтогарячий (листяні ліси) та бордовий (хвойні ліси) колір. Смарагдово-зелені — грунти (темні відтінки) та суха трава (світлі відтінки). Водойми мают темно-синій колір.
Наведений космічний знімок було класифіковано з виділенням трьох класів: листяних лісів, хвойних лісів та водойм (рис. 1, у центрі). Існує й четвертий клас — некласифіковані пикселі, тобто все, що не належить до перших трьох класів. Справа на рисунку 1 стоїть еталонне зображення, що створене на базі ручної векторизації. Ми будемо використовувати його для розрахунку матриці помилок.
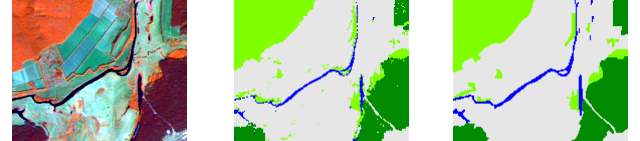
Рис. 1. Фрагмент знімка Landsat, класифікований знімок, еталонне зображення
Створення матриці помилок
1) Щоби створити матрицю помилок, оберіть у Тулбоксі Classification→Post Classification→Confusion Matrix Using Ground Truth Image.
2) З’явиться вікно, у якому треба обрати зображення класифікації, точність якого ми оцінюємо. Оберіть це зображення та натисніть ОК.
3) Далі з’явиться нове вікно, у якому треба обрати зображення класифікації, що є еталоном. Оберіть еталон для порівняння та натисніть ОК.
4) Після того, як були обрані обидва зображення, необхідно вказати відповідність між конкретними класами зображення класифікації та еталонного зображення. Цю операцію необхідно виконати у вікні Match Classes Parameters. Зіставте класи еталона й зображення класифікації в пари порівняння. Для цього виділіть обидва класи та натисніть кнопку Add Combination.

Рис. 2. Встановлення відповідності між класами зображення класифікації та класами еталонного зображення
5) Після зіставлення класів у порівняльні пари відкриється віконце, де необхідно налаштувати параметри матриці помилок. У цьому віконці є три групи параметрів, що розташовані згори донизу:
– одиниці, у котрих треба виводити значення в чарунках матриці помилок (Output Confusion Matrix in)
– створення звіту про точність (Report Accuracy Assessment)
– створення зображення помилок (Output Error Images)
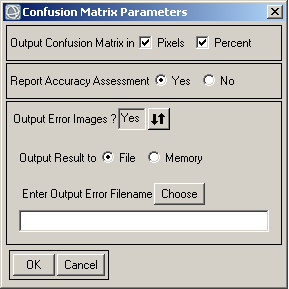
Рис. 3. Налаштування параметрів матриці помилок
Значення в чарунках матриці помилок можна виводити в пікселях або відсотках. Щоб обрати перший варіант, навпроти Output Confusion Matrix in поставте галочку на Pixels. Для обрання другого варіанту позначте галочкою Percents. Також можна створити одночасно дві матриці помилок — одну зі значеннями в пікселях, другу — у відсотках. Для цього треба поставити обидві галочки.
Якщо є бажання побачити звіт про точність класифікації, поставте перемикач Report Accuracy Assessment на значення Yes. У протилежному випадку оберіть No.
Щоби подивитися, які пікселі були класифіковані правильно, а які помилково, треба для опції Output Error Images встановити значення Yes.
Після налаштувння всіх параметрів, натисніть OK і, нарешті, у вікні Class Confusion Matrix з’явиться розрахована матриця помилок (рис. 4).
Аналіз матриці помилок
Розберемо, що відображено зверху донизу у вікні Class Confusion Matrix (рис. 4).
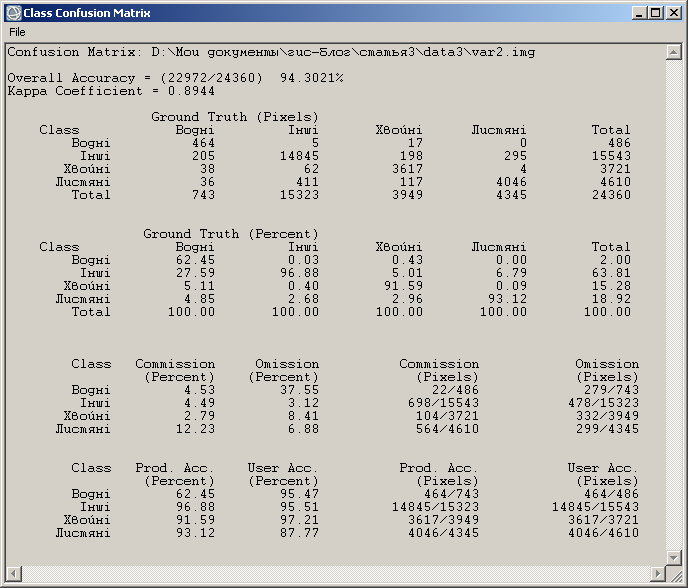
Рис. 4. Матриця помилок
У першому рядку міститься шлях до файлу зображення класифікації, точність якого ми оцінювали. Далі загальна точність класифікації та каппа-коефіцієнт. Нижче міститься вже сама матриця помилок. Спочатку в пікселях, а потім у відсотках. Нижче матриці помилок звіт про точність класифікації: значення комісії та омісії для кожного класу.
Загальна точність класифікації для зображення, що наведено на рисунку 1, приблизно 94 %. Тобто 94 % пікселів дешифровані правильно, а 6 % пікселів дешифровані з помилками. Це доволі висока точність.
Також точність кожного окремого класу показана в матриці. З трьох класів найбільша точність класифікації в листяних лісів (93,12 %), далі йдуть хвойні ліси (91,59 %), а найменша точність класифікації у водойм (62,45 %). Якщо точність для перших двох класів можна вважати високою, то останньому класу явно її бракує.
Далі проаналізуємо розмір комісії та омісії кожного класу. Можна побачити, що у водойм та хвойних лісів переважають помилки омісії. А в листяних лісів навпаки, переважають помилки комісії.
Який варіант співвідношення комісії та омісії кращий, залежить від мети та стратегії дешифрування. У деяких випадках головним може бути розпізнати всі пікселі, що насправді належать до класу, навіть за рахунок зростання кількості помилкових приписок. В інших випадках краще мати пропуски, ніж зараховувати до складу класу пікселі, що насправді йому не належать. Але зазвичай користувач не схиляється до цих граничних варіантів, а шукає компроміс між ними.
Аналіз зображень помилок
Зображення помилок класифікації — це багатошарове растрове зображення. Кожний його шар відповідає окремому класу. В ENVI зображення помилок показує лише помилки пропускання. У кожному шарі є тільки два значення пікселів — 0 або 1. Перше значення — це правильно впізнані пікселі, а друге значення — впущені пікселі.
Зображення помилок зручніше аналізувати, якщо накласти його поверх еталонного зображення та зробити напівпрозорим. Для цього треба виконати такі кроки.
1) У таблиці змісту перетягніть шар зображень помилок нагору, щоби він був вище за шар еталонного зображення (рис. 5).
2) Відключіть усі класи еталонного зображення, крім того, для котрого ми візуалізуємо помилки класифікації.
Рис.5. Зображення помилок та еталон класифікації в таблиці змісту
3) Натисніть правою кнопкою миші на ім’я шару. Оберіть у контекстному меню команду Change RGB Bands… З’явиться вікно, у якому можна обрати конкретний шар зображення помилок (рис. 6).
Рис. 6. Вибір шару для відображення
4) Змініть значення прозорості зображення помилок за допомогою бігунка Transparency з 0, наприклад, на 40 (рис. 7).
![]()
Рис. 7. Бігунок прозорості
Візуалізація помилок для кожного з трьох класів показана на рисунку 8. Розглядаючи ці зображення, можна зробити деякі висновки про просторові закономірності в помилках. Так у цьому прикладі помилки пропускання виникли насамперед на межах об’єктів, що були дешифровані. Великі об’єкти були дешифровані краще, ніж дрібні, тобто частка помилок від загальної площі більше в дрібних об’єктів. При цьому дрібні об’єкти однакової площі мають різну частку помилок. Компактні об’єкти були дешифровані краще, ніж витягнуті.
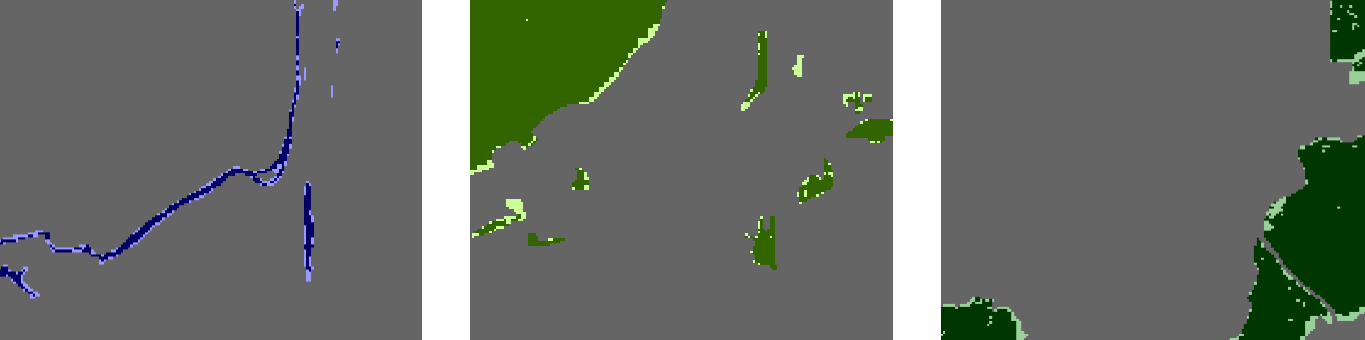
Рис.8. Зображення помилок (водойми, листяні ліси, хвойні ліси)
У завершенні цього посту ще раз повернемося до мети створення матриці помилок. На початку писалося, що розрахунок матриці робиться для оцінки точності класифікації. Це дійсно так, але це ще не все. Аналіз матриці помилок та зображень помилок дозволяє виявити джерела помилок, а на цій підставі вже можна шукати засоби підвищення точності класифікації.




This article gives incorrect formulas for Omission and Commission errors. Errors of commission should be == incorrect in row / total in row; Similarly omission errors should be calculated within the columns. The author had it the other way around.
Shouldn’t the omission error (resp. commission error) be dependent on the FN (resp. FP) respectively? It seems in this tutorial that the formulas are quite different from what I came across in the literature (the omission representing missed classification while the commission error is for false alarms).
Pay attention to the size of the matrix in the article. FN, TN, FP, FN, TPR, FPR, TNR, FNR is for a matrix with the size 2×2. The article describes the evaluation of the quality of classification with the number of classes greater than 2. For example: http://www.harrisgeospatial.com/docs/CalculatingConfusionMatrices.html
Multiple classes can be reduced to two. For example, one class is A, another class is B and C. Then in our example for the class A:
TP=aA
TN=bB+cC
FP=aB+aC
FN=bA+cA