

When setting the procedure for calculating many criteria for spatial statistics, you must specify the distance threshold. It is used to find the neighbours of each object and to determine the spatial scales that show the impact of objects on each other. These spatial weights are one of the variables in the formulas for calculating the criteria of spatial statistics.
Theory
The result of the calculation of statistical criteria depends very much on the threshold value of the distance. Therefore, there is always a question – how to determine its optimal value? Here, first, you need to find out for yourself, which is, in fact, the optimal value. When we use the methods of spatial statistics, we are usually interested in the presence of spatial patterns. That is, we try to find signs of group distribution of the characteristics of the objects being investigated. And if the distribution in space is random or uniform, this indicates the probable lack of spatial patterns. Thus, the optimal distance threshold for neighbouring searches and the determination of spatial weights is the distance at which the trend toward group distribution is most pronounced.
But how to make the right decision how to determine the optimal value of the threshold of the distance? There are two options here. The first option is to know the object and territory of the study well, to understand the essence of the processes that determine the formation of spatial patterns. Relying on your research experience will allow you to make the right decision.
If there is not enough research experience, then the second option will be to estimate the spatial autocorrelation (based on the Moran’s I criterion) with all possible distances. To do this, choose a minimum distance value and make a calculation for it. Then step by step increase the distance by a specific value and make new calculations. Therefore, this stepwise procedure is called estimation of spatial autocorrelation at different distances or shortened – incremental spatial autocorrelation. The distance at which the statistical significance of the positive autocorrelation is greatest is the optimal distance threshold.
For Moran’s I, statistical significance is estimated using the z-score. The larger it is, the more the statistical significance of spatial clusterization, that is, there is a more pronounced group distribution. And the maximum negative values of z-score indicate the most significant uniform spatial distribution.
The results of a stepwise estimation of spatial autocorrelation are usually displayed as a graph of the z-score. On this graph, along the X-axis, there is the distance value, along the Y-axis, the z-score value. The peak on this graph indicates the distance with the most pronounced clustering. In some cases, the curve of values of the z-score may have several peaks. This means that there are different spatial patterns at different levels of scale. Therefore, the purpose of incremental estimation of spatial autocorrelation is not limited to the selection of the optimal search radius. It also allows you to analyze how spatial patterns change with a change in the scale of the study.
The calculation of the Moran’s I criterion for all possible search radiuses can give a lot of interesting material for analysis. But it takes a lot of time. Yes, repeating the same operations over and over is tiring. Therefore, now there are software solutions that allow you to automate this process, reduce it to one operation. In this post, we will have a look at how it is done in the ArcGIS program.
Practice
We will examine incremental spatial autocorrelation using an example from the post about Moran’s I. It analyzed the proportion of inhabitants of some districts of Belgorod region, which, according to the 2002 census, were born outside of the Belgorod region (Fig. 1). It is necessary to determine at what distance spatial autocorrelation is the most significant (meaning statistical significance).
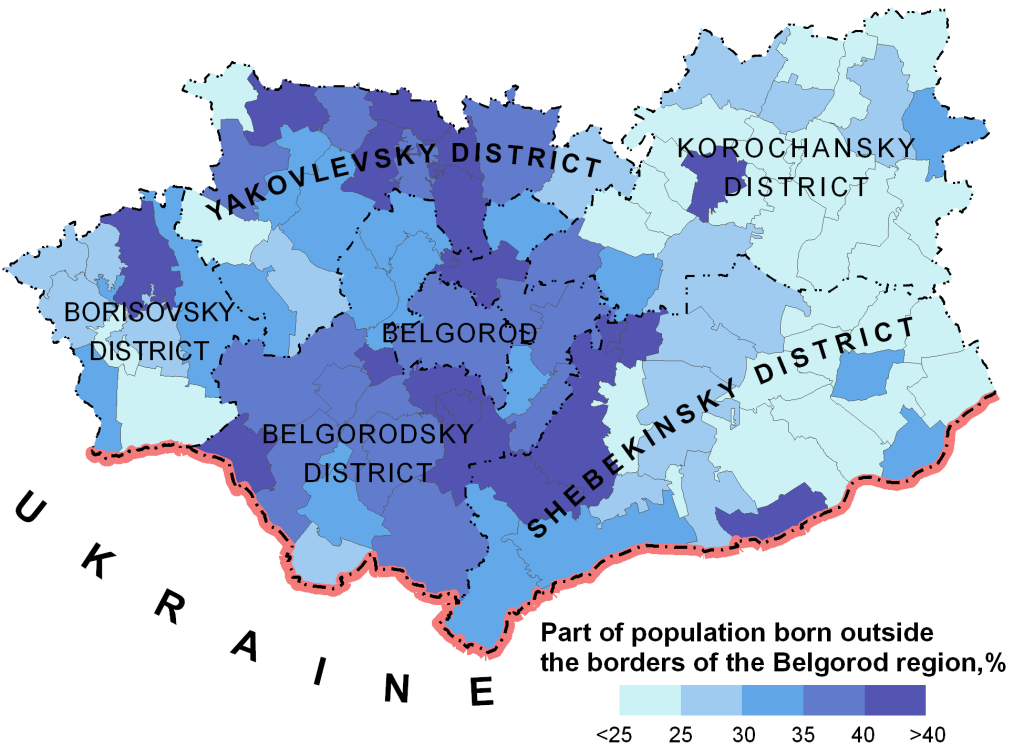
Fig.1 The share of the population born outside the Belgorod region
1) To start the step-by-step calculation of the general Moran’s I, we need to select the Spatial Statistic Tools → Analyzing Patterns → Incremental Spatial Autocorrelation command in ArcGIS’s Toolbox (Figure 2).
Fig. 2. Tool for step-by-step calculation of the Moran I in ArcToolbox
2) When the tool is launched, a setup window will appear in which you need to configure nine parameters. The first three (if you count from top to bottom) are required. Other parameters can be left blank or by default (Figure 3).
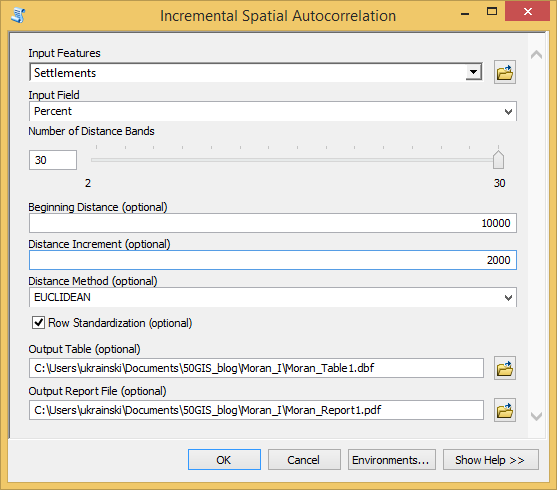
Fig. 3 Settings window
3) The first two mandatory parameters are the vector layer for analysis and a column from the attribute table of this layer that contains the metric for analysis. The vector layer must be specified in the Input Features field. After that, in the Input Field list, the attributes of the selected layer will appear. Of these, we must choose an indicator for which we will calculate Moran’s I.
4) The third mandatory parameter is the number of distances (Number of Distance Bands) for which Moran’s I will be calculated. It can be from 2 to 30. The exact value can be set using the slider. You can also enter it from the keyboard in the input line to the left of the slider.
5) You can then (but not necessarily) set the Beginning Distance and Distance Increment. These parameters are not set by default. The program itself defines the values according to the size of the territory covering the vector layer and the size of objects in this layer.
In our example (Fig. 3), the following values are set manually: the initial distance is 10,000 meters, the distance increment is 2000 meters.
6) From the Distance Method list, you can choose a way to calculate the distance. There are two options: Euclidean distance (default) and Manhattan distance. How these are different can be read here.
7) The Row Standardization switch adjusts the spatial weights standardization. By default, standardization is not enabled. This means that the absolute (not standardized) values of spatial weights will be used to calculate Moran’s I. If you tick the Row Standardization, instead of the absolute values, standardized values will be taken into account, that is, divided by the sum of spatial weights.
8) The final settings to configure are ways to save your results. By default, the result is not saved. You can view it only in the open ArcGIS session by using the Geoprocessing menu option.
In addition, you can save the result as a report to a .pdf format and a table to a .dbf format. To do this, the Output Table and Output Report File fields must specify the storage location and filename.
9) Once all the process parameters are configured, you need to click OK and you can proceed to the analysis of the results.
10) To view the results, you must select Geoprocessing → Results from the ArcGIS menu. This will open a window with information messages describing the performed operation and its results (fig. 4).
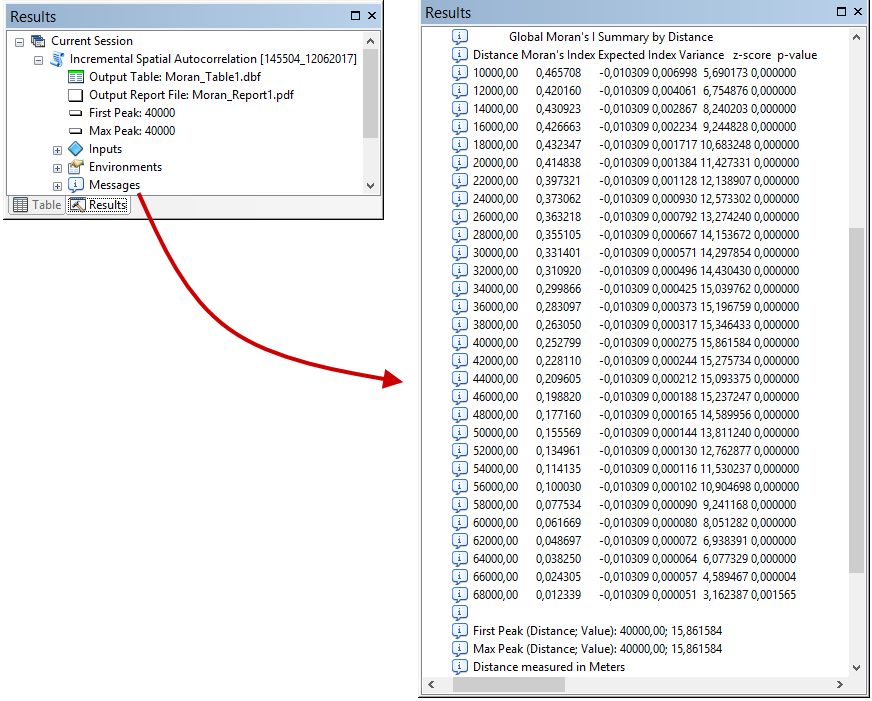
Fig. 4. Information reports with the results of stepwise calculation of the Moran’s I
In the messages, the first thing that is indicated is the distance at which the first peak of the z-score was observed. Then the distance at which the z-score reaches the highest value (Max Peak) is indicated. In our case, both peaks coincide and are fixed at a distance of 40,000 meters. In order to analyze the results in more detail, it is necessary to expand Messages drop-down in the Results (fig. 4). Here, for each increment, the actual value of Moran’s I, the expected value of Moran’s I, the z-score and the p-value are shown.
11) If you set the option to save the results as a table, then the a .dbf file is added to the table of contents. This table can be opened and viewed. In Figure 5, we see that this table contains the same results as in the Messages item (Figure 4).
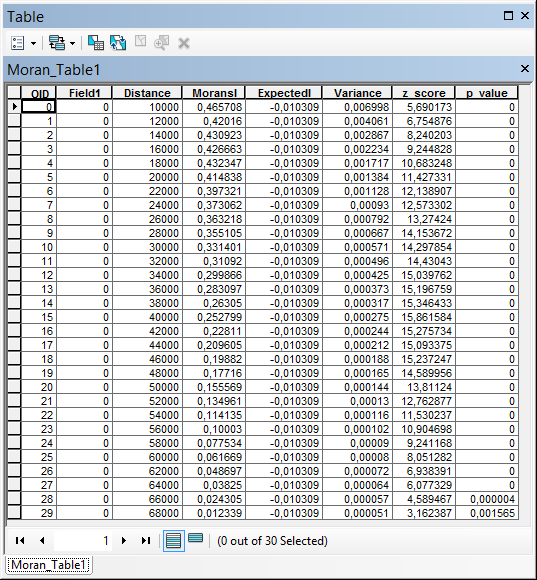
Fig. 5. Table with the results of incremental calculations of the Moran’s I index
12) If you set the report creation option, a .pdf file will be created. In addition to the data contained in the Results window and the dbf-table, there is a z-score graph in this file (Fig. 6).
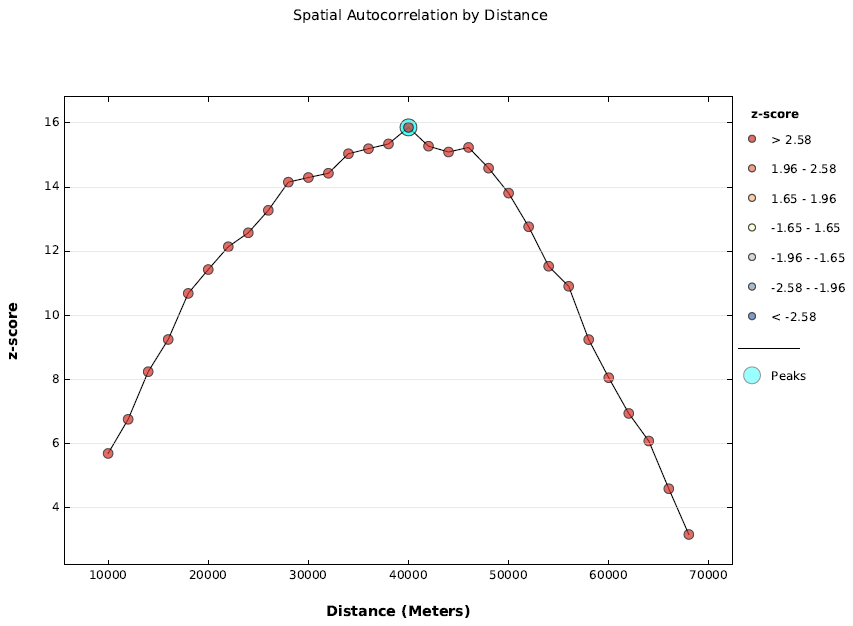
Fig.6. Dependence of z-score on distance
The colour of the points in the graph indicates the statistical significance. More about the relationship between the values of the z-score and the p-values can be read here. Yellow points are statistically insignificant indications of a tendency to random distribution in space. The points of shades of blue are a statistically significant tendency to even distribution. The points of red shades are a statistically significant trend toward group distribution.
In our case, we have a statistically significant grouping on all distances. As the distance grows, z-scores are initially increasing, and after 40,000 meters they start to decrease. This peak on the graph is marked with a cyan halo.
Why, with a distance of 40 kilometres, the tendency to group the values in space is most pronounced – it’s difficult to say. The answer to this question requires a separate study. But it is striking that the size of the distance with the most significant grouping is close to the average width of the administrative area. Perhaps there is a mediocre influence of the configuration of the administrative division on socio-demographic processes.


Методы пространственной статистики универсальны. Они подходят для любых пространственных данных, и, теоретически, могут применяться в любой отрасли. Но пространственная статистика – это весьма молодая отрасль статистики, поэтому она еще не везде укоренилась. Более-менее активно она стала развиваться только с 70-х годов. Некоторые методы были разработаны совсем недавно, в 90-е годы.
Сейчас чаще всего пространственная статистика применяется в экономической, социальной и политической географии и смежных с ней отраслях. Применяют как на внутригородском уровне, так и на уровне региона и страны в целом.
Типичные примеры изучения пространственной автокорреляции из практики отечественных гуманитариев:
goo.gl/BmCwGK
goo.gl/CjrxCt
goo.gl/1Hgck7
goo.gl/D5agi9
Вторая отрасль, где используют методы пространственной статистики – это экология. Здесь у нас подобные работы встречаются реже (за рубежом пространственная статистика чаще используется в экологии). Например:
goo.gl/3iymYZ
goo.gl/nsCqGA
Обычно использованием общего критерия Морана I не ограничиваются. После обнаружения положительной автокорреляции начинают выделять пространственные кластеры с помощью локального критерия Морана I.
Дякую за статтю
Які реальні (в науці, бізнесі) приклади використання алгоритму Morans’ I?